
NoSQL중에 가장 주목받고 있는 Cassandra의 개념은 결코 어렵지 않습니다. 하지만 어떻게 생각하면 정말 어렵습니다. 처음 스프링을 공부할때 AOP(Aspect Oriented Programming)라는 개념이 어렵게 다가왔던 시절이 생각이 납니다. 그당시에 AOP가 어려웠던것은 바로 내 머리속에 너무나도 자연스럽게 자리잡고 있는 OOP(Object Oriented Programming) 때문이죠. 바로 객체 지향이 너무나도 머리속에 자연스럽게 자리잡고 있었기 때문에 AOP를 이해하는데 많은 방해가 되었습니다.
카산드라도 마찬가지로 이해를 하는데 불필요한 방해요소가 있습니다. 바로 RDBMS(Relational DataBase Management System)입니다. Oracle, MSSQL, MySQL등을 아주 많이 다뤄 보셨다고요? 그렇다면 카산드라가 정말 어려울 것입니다. 오히려 모르는것이 도움이 될 수 있습니다. 카산드라를 공부하긴 공부해할꺼 같은데 시작해서 인터넷의 글을 검색하다보면 답답해 미쳐버릴 지경입니다. 도대체 SELECT는 어떻게 해야 할까, JOIN은 어떻게 한다는거지? 두개 이상의 데이터를 어떻게 조합하여 사용할수 있는걸까? 하물며 Sub-Query는 어떻게 사용하는거지? 비슷한 개념이라도 있긴한가?
카산드라를 조금만 살펴보시면 알 수 있습니다만 없습니다. 하물며 그 기본적인 개념인 JOIN의 개념조차 없습니다. 정말 단순하게 set/get으로만 이루어진 단순한 명령뿐입니다. 도대체 이런 단순한 시스템을 뭘 믿고 엄청난 대용량의 데이터를 보관한단 말일까요? 우선 카산드라를 이해하기 위해서는 머리속에서 RDB라는 개념을 지우실 필요가 있습니다. 좀더 나아가 DB라고 하면 떠오르는 무엇인가를 지울 필요가 있습니다. DB == SQL 일까요? 사실 저는 그렇게 생각해오고 있었습니다. DB는 말그대로 데이터 저장소쯤으로 이해하시면 이제 쉬워집니다. 여기서는 SQL이라는것도 쿼리문이라는 단어도 필요가 없습니다. 이와 관련하여 멋진 블로그글이 있어 옮겨 적어봅니다.
1. 조각들
컬림(Column)
컬럼은 데이터를 이루는 가장 작은 단위입니다. DB수업 시간에는 일명 튜플이라고 배우는것과 비숫합니다. 컬럼은 이름과 값을 가지며 데이터가 갱신된 시각이 기록됩니다.
{ // 이것이 컬럼입니다.
name: "emailAddress",
value: "arin@example.com",
timestamp: 123456789
}
이것이 값을 표현하는 작은 단위의 전부입니다. 앞으로는 좀더 편하게 생각하기 위해서 타임스탬프값은 무시하도록 하겠습니다. 단지 키/밸류만 생각하도록 합시다. 컬럼들의 이름과 값은 둘다 바이너리(기술적인 용어로 byte[])로 저장이 되며 길이에는 제한이 없습니다.
슈퍼컬럼(SuperColumn)
슈퍼컬럼은 이름과 값으로 이루어져 있습니다. 여기서 값에는 제한이 없는 숫자만큼의 컬럼들을 포함할 수 있습니다. 컬럼의 이름이 각각의 키(Key)가 됩니다.
{ // 이것이 슈퍼컬럼입니다
name: "homeAddress",
// 무한한 컬럼들을 가질 수 있습니다
value: {
// note the keys is the name of the Column
street: {name: "street", value: "1234 x street", timestamp: 123456789},
city: {name: "city", value: "san francisco", timestamp: 123456789},
zip: {name: "zip", value: "94107", timestamp: 123456789},
}
}
여기서 미리 알아두어야 할점은 슈퍼컬럼은 사용하지 않을 수 있습니다. 현재의 슈퍼컬럼이라는 개념은 실제로는 컬럼패밀리(ColumnFamily)에 가깝습니다. 하지만 일단은 이해를 돕기 위해서 쓰는 글이니 그러려니 하고 봐주세요.
컬럼(Column) VS 슈퍼컬럼(SuperColumn)
컬럼과 슈퍼컬럼은 둘다 이름과 값으로 이루어진 튜플입니다. 하지만 가장 큰 차이는 컬럼의 값은 문자열(String)인데 반해 슈퍼컬럼의 값은 컬럼들의 Map입니다. 이것이 무슨말이냐 하면 슈퍼컬럼의 값은(여기서의 값은 컬럼의 이름이 됩니다) 다양한 형태의 데이터 타입을 가질 수 있습니다. 다른 작은 차이로는 슈퍼컬럼은 컬럼과 달리 타임스탬프(timestamp) 컴포넌트를 가지지 못합니다.
본격적으로 시작하기에 앞서
JSON문법을 예시로 들며 설명을 하고 있습니다만 좀더 간단하게 표현하기 위해 타임스탬프(timestamp)값을 빼기로 하고 컬럼과 슈퍼컬럼의 이름부분을 제거하겠습니다. 결과적으로 위의 슈퍼컬럼에서 보였던 예제는 다음과 같이 변할 수 있습니다.
homeAddress: {
street: "1234 x street",
city: "san francisco",
zip: "94107",
}
2. 그룹으로 묶기
지금까지는 컬럼과 슈퍼컬럼의 단순한 단일 구조에 대해 설명해 보았습니다. 이번에 소개해 드릴 구조는 컬럼패밀리(ColumnFamily)라고 불리는데 Standard와 Super라는 모습을 가집니다.
컬럼패밀리(ColumnFamily)
컬럼패밀리는 무한한 로우(Row)를 가지는 구조를 가집니다. 여기서 로우라는 단위를 사용하는것은 RDBMS의 그 로우라고 생각하시면 쉬울듯 합니다. 각각의 로우는 키와 컬럼들의 집합인 Map을 값으로 가집니다.
UserProfile = { // 이것이 컬럼패밀리입니다
phatduckk: { // 이것은 컬럼패밀리안에 있는 키입니다
// 이 로우는 무한한 컬럼들을 가질 수 있습니다
username: "phatduckk",
email: "phatduckk@example.com",
phone: "(900) 976-6666"
}, // end row
ieure: { // 이것은 또다른 컬럼패밀리안의 키입니다
// 또다른 이 로우 역시 무한한 컬럼들을 가질 수 있습니다
username: "ieure",
email: "ieure@example.com",
phone: "(888) 555-1212"
age: "66",
gender: "undecided"
},
}
위의 모습은 마치 자바의 HashMap이나 Objective-C의 Dictionary 또는 일종의 배열을 생각하게 만듭니다. 여기서 또한 느껴야 할점은 여기에는 그어떤 스키마도 존재하지 않는다는 것입니다. 로우들은 미리 정의된 컬럼들의 리스트를 가지지 않습니다. 위의 예제에서 알 수 있듯이 ieure의 경우에는 age와 gender라는 값을 추가로 가지고 있습니다. 이것은 100% 유연합니다. 어떤 로우는 2000개의 컬럼을 가지고 있고 어떤 컬럼은 단지 2개의 컬럼을 가지고 있을수도 있습니다. 하나의 로우는 하나의 컬럼을 가지고 있어야만 합니다. 이것이 카산드라의 schema-less 관점입니다.
컬럼패밀리는 Super가 될 수 있습니다.
이제 컬럼패밀리의 Standard와 Super타입에 대해 알아볼 시간입니다. 지금까지 경험한 컬럼패밀리는 Standard 타입입니다. Standard타입이라는것은 모든 로우들이 일반적인 컬럼들의 집합 Map을 가짐을 의미합니다. 이것은 슈퍼컬럼이 존재하지 않음을 의미합니다.
컬럼패밀리의 타입이 Super가 된다는것은 쉽게 생각하면 Standard의 반대로 생각해 보면 됩니다. 각각의 로우는 슈퍼컬럼의 집합인 Map을 가지게 됩니다. 슈퍼컬럼에 대해서는 위에서 언급을 했으니 자세한 내용은 넘어가도록 하겠습니다.
AddressBook = { // Super타입의 컬럼패밀리입니다
phatduckk: { // 슈퍼컬럼패밀리안의 키입니다
// 이곳에는 친구들의 주소록정보가 있습니다
// 이 로우에는 무한히 많은 슈퍼컬럼을 가질 수 있습니다
// 로우의 키는 슈퍼컬럼의 이름이 됩니다
// 각각의 슈퍼컬럼들은 주소록 데이터가 됩니다
friend1: {street: "8th street", zip: "90210", city: "Beverley Hills", state: "CA"},
John: {street: "Howard street", zip: "94404", city: "FC", state: "CA"},
Kim: {street: "X street", zip: "87876", city: "Balls", state: "VA"},
Tod: {street: "Jerry street", zip: "54556", city: "Cartoon", state: "CO"},
Bob: {street: "Q Blvd", zip: "24252", city: "Nowhere", state: "MN"},
...
// 무한한 숫자의 슈퍼컬럼을 가질 수 있습니다
}, // 로우 끝
ieure: { // 또다른 슈퍼컬럼패밀리안의 키입니다
// ieure를 위한 주소록 정보의 전체가 있습니다
joey: {street: "A ave", zip: "55485", city: "Hell", state: "NV"},
William: {street: "Armpit Dr", zip: "93301", city: "Bakersfield", state: "CA"},
},
}
키스페이스(Keyspace)
키스페이스는 데이터의 그룹의 가장 바깥쪽에 위치하는 개념입니다. 모든 컬럼패밀리가 하나의 키스페이스 안에 포함됩니다. 키스페이스는 일반적으로 어플리케이션의 이름과 동일합니다. 키스페이스는 다수의 컬럼패밀리를 가질 수 있음을 알 수 있었습니다. 하지만 이것이 각각의 컬럼패밀리들간에 어떠한 관계를 형성하는것은 아닙니다. 이것은 MySQL의 테이블(Table)과 같은 개념이 아닙니다. 컬럼패밀리들을 JOIN할수도 없습니다. ColumnFamily_1이 A라는 로우값을 가진다고 해서 ColumnFamily_2도 가질것이라는것을 의미하지는 않습니다.
3. 정렬
지금까지 다양한 데이터가 어떤식으로 저장되는지에 대해 알아보았습니다. 이제 중요하게 알아보아야 할 요소로는 정렬이 있을것 같습니다. 카산드라는 SQL과 같은 쿼리를 통해 데이터를 가져오는 DB가 아닙니다. 어떻게 데이터를 정렬해서 원하는 데이터만을 가져오는 방식을 특정 짓기는 어렵습니다. 데이터는 클러스터에 삽입되는 그 순간부터 정렬된 채로 저장이 됩니다. 그리고 영원히 정렬된채로 존재하게 됩니다. 이것은 읽기시에 가공할만한 속도의 향상을 가져다 줍니다. 하지만 이러한 데이터 접근 패턴에 맞게 데이터모델을 잘 설계하는것이 중요합니다.
컬럼은 그들을 포함하고 있는 로우안에서 컬럼의 이름으로 정렬이 됩니다. 이것은 매우 중요합니다. 컬럼패밀리의 CompareWith옵션에 의해 정렬에 대한 규칙도 달라지게 됩니다. 정렬을 위해서는 다음과 같은 방식이 제공됩니다.
각각의 옵션들은 컬럼의 이름들을 어떻게 다른 데이터로 식별할 수 있는지에 대한 가이드라인을 제시해 줍니다. 예를 들자면 LongType의 경우에는 컬럼의 이름이 64비트 Long으로 이루어지게 됩니다. 다음의 예시를 통해 이것이 무엇을 의미하는지 알아보도록 합시다.
// 로우안의 각각의 컬럼들이 정렬되지 않은채로 데이터가 보관되어있습니다
// 카산드라는 절대로 정렬되지 않은 상태로 데이터를 보관하지 않습니다.
// 이것은 단지 예제일뿐입니다.
{name: 123, value: "hello there"},
{name: 832416, value: "kjjkbcjkcbbd"},
{name: 3, value: "101010101010"},
{name: 976, value: "kjjkbcjkcbbd"}[/code]
이제 LongType으로 설정을 할 경우에 컬럼들이 어떻게 정렬된 채로 보관이 되는지 알아봅시다.
[code]<ColumnFamily CompareWith="LongType" Name="CF_NAME_HERE"/>
// 각각의 컬럼의 이름들이 64bit Long으로 처리되었습니다
// 결과적으로 숫자로 인식을 하여 정렬이 되었습니다
{name: 3, value: "101010101010"},
{name: 123, value: "hello there"},
{name: 976, value: "kjjkbcjkcbbd"},
{name: 832416, value: "kjjkbcjkcbbd"}
위의 예시에서 알 수 있듯이 컬럼들의 이름은 64bit Long으로서 서로 값을 비교하여 정렬 되었습니다. CompareWith옵션을 바꿔봄으로써 이같은 결과와 다른 결과를 볼 수 있습니다. UTF8Type으로 정렬을 할 경우에 다음과 같은 정렬 결과를 보여줍니다.
<ColumnFamily CompareWith="UTF8Type" Name="CF_NAME_HERE"/>
// 각각의 컬럼 이름들이 UTF8문자열로 처리되었습니다
{name: 123, value: "hello there"},
{name: 3, value: "101010101010"},
{name: 832416, value: "kjjkbcjkcbbd"},
{name: 976, value: "kjjkbcjkcbbd"}
결과가 완벽하게 다른것을 알 수 있습니다. 이러한 정렬의 법칙은 슈퍼컬럼에게도 영향을 미칩니다. 하지만 이렇게 정렬된 슈퍼컬럼들안의 로우들 역시도 어떻 규칙으로 정렬을 할지를 설정할 수 있습니다. 각각의 슈퍼컬럼들 안의 컬럼들의 정렬은 CompareSubcolumnsWith의 값으로 결정할 수 있습니다.
// 2개의 슈퍼컬럼을 가지고 있습니다
// 현재 랜덤한 정렬상태를 가지고 있습니다
{ // 첫번째 슈퍼컬럼
name: "workAddress",
value: {
street: {name: "street", value: "1234 x street"},
city: {name: "city", value: "san francisco"},
zip: {name: "zip", value: "94107"}
}
},
{ // 또다른 슈퍼컬럼
name: "homeAddress",
value: {
street: {name: "street", value: "1234 x street"},
city: {name: "city", value: "san francisco"},
zip: {name: "zip", value: "94107"}
}
}
위의 데이터를 가지고 CompareSubcolumnsWith와 CompareWith옵션을 둘다 UTF8Type으로 변경해 보았을 경우 다음과 같은 결과를 보이게 됩니다.
{
{
// 이 로우가 첫번째 위치로 정렬되었습니다
name: "homeAddress",
// 슈퍼컬럼안의 컬럼들 역시 정렬되었습니다
value: {
city: {name: "city", value: "san francisco"},
street: {name: "street", value: "1234 x street"},
zip: {name: "zip", value: "94107"}
}
},
name: "workAddress",
value: {
// 슈퍼컬럼안의 컬럼들 역시 정렬되었습니다
city: {name: "city", value: "san francisco"},
street: {name: "street", value: "1234 x street"},
zip: {name: "zip", value: "94107"}
}
}
위의 예제에서 알 수 있듯이 두개의 옵션을 가지고 다양한 형태로 데이터를 가져올 수 있습니다. 잊지 마셔야 할점은 CompareSubcolumnsWith은 슈퍼컬럼이 존재하는 즉 컬럼패밀리의 타입이 Super일 경우에나 사용할 수 있다는 점입니다. 설계상에 적절히 적용하시면 될듯합니다.

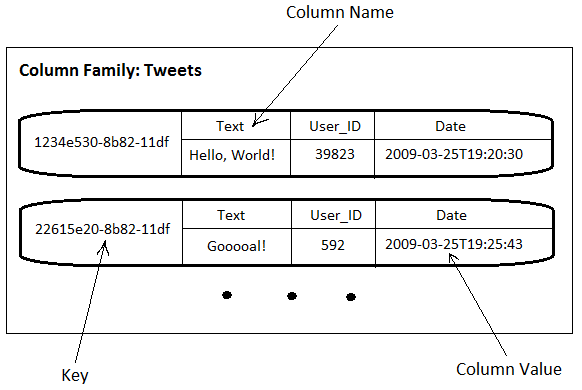 Tweets라는 컬럼 패밀리는 다음과 같은 트윗의 레코드를 가지고 있습니다. 레코드의 키는 Time UUID 타입이며 트윗을 받을때마다 생성됩니다. 하나의 레코드는 3개의 컬럼을 가지고 있으며(여기서 슈퍼컬럼은 사용하지 않습니다) 컬럼은 트윗에서 보여지는 간단한 내용을 입력해 보았습니다. 이러한 구조는 RDB에서 어떻게 데이터를 저장하는지와 비슷한 형태를 보여준다고 볼 수 있습니다.
Tweets라는 컬럼 패밀리는 다음과 같은 트윗의 레코드를 가지고 있습니다. 레코드의 키는 Time UUID 타입이며 트윗을 받을때마다 생성됩니다. 하나의 레코드는 3개의 컬럼을 가지고 있으며(여기서 슈퍼컬럼은 사용하지 않습니다) 컬럼은 트윗에서 보여지는 간단한 내용을 입력해 보았습니다. 이러한 구조는 RDB에서 어떻게 데이터를 저장하는지와 비슷한 형태를 보여준다고 볼 수 있습니다.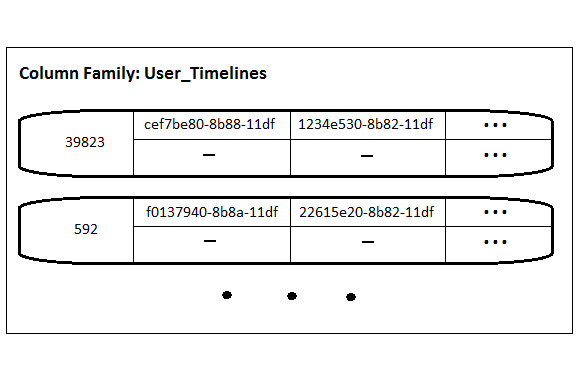
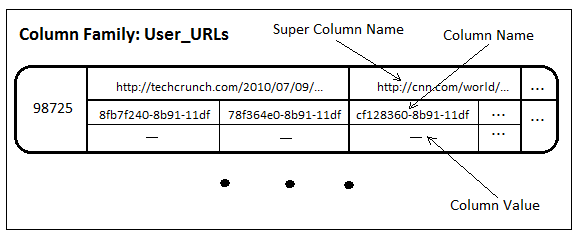 User_URLs컬럼패밀리에서는 URL들을 키로써 저장하고 내포하는 컬럼들은 이것을 언급한 트윗의 ID를 저장하고 있는것을 알 수 있습니다.
User_URLs컬럼패밀리에서는 URL들을 키로써 저장하고 내포하는 컬럼들은 이것을 언급한 트윗의 ID를 저장하고 있는것을 알 수 있습니다.