
새롭게 등장한 카산드라의 데이터 모델은 생각보다 간단하면서도 생각보다 복잡합니다. 기존의 RDBMS에 익숙한 개발자들은 카산드라의 데이터 모델을 공부하기 위해 많은 시간을 들여야 할지도 모릅니다. 이 글은 이러한 카산드라의 데이터모델에 대하여 간단하게 설명을 해보는 글입니다.
1. 카산드라는 키/밸류 모델에 기반합니다.
카산드라의 데이터베이스는 컬럼패밀리(ColumnFamily)라는것으로 이루어져있습니다. 이 컬럼패밀리라는것은 키/밸류 기반 데이터의 모음입니다. 이러한 용어가 어렵다면 그냥 간단하게 키/밸류 모델을 생각하시면 됩니다. 굳이 RDB의 개념과 비교를 해보자면 컬럼패밀리는 테이블(Table)로 키/밸류 쌍은 테이블의 레코드(Record)로 볼 수 있겠네요.
2. 카산드라는 두단계의 뎁스를 내포하는 키/밸류 모델입니다.
카산드라는 기존의 일반적인 키/밸류 모델을 좀더 확장한 모양세를 갖추고 있습니다. 첫번째 레벨인 레코드의 값들은 순서대로 저장된 키/밸류 데이터쌍입니다. 이러한 키/밸류 쌍은 컬럼(Column)이라고 부릅니다. 키/밸류쌍에서의 키는 곧 컬럼의 이름이 됩니다. 좀 다른말로 표현해보자면 컬럼패밀리의 레코드들은 키를 가지고 있고 한개이상의 컬럼으로 이루어져있습니다. 이러한 내포 구조는 최소한 한개의 컬럼을 가져야 하며 강제적인 조건입니다.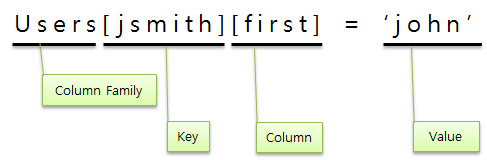
3. 컬럼이나 슈퍼컬럼의 이름은 두가지 방법으로 사용가능합니다. – 이름 또는 값(참조값)
첫번째로 컬럼이나 슈퍼컬럼의 이름은 말그대로 이름의 역할을 합니다. 예를 들면 사용자 정보를 담고 있는 레코드라면 컬럼의 이름이 사용자의 정보를 담고 있는 User의 이메일정보를 담고 있다고 하여 Email이 될 수 있습니다. 이것은 말그대로 어떤 값인지를 식별하는 용도로 사용될 수 있습니다.
두번째로 이름은 값을 저장하는 용도로도 사용될 수 있습니다. 블로그를 예로 들어보면 컬럼의 이름이 각각의 글에대한 구분자가 될 수 있습니다. 컬럼 네임을 데이터로 쓸수 있는 이유로는 카산드라에서는 컬럼의 숫자에 대한 제한이 없이 무한하다는 것이고 이름의 값은 Byte Array로써 어떠한 값이라도 인코딩하여 사용할 수 있다는 점입니다.
4. 컬럼(Column)이나 슈퍼컬럼(Super Column)들은 이름순으로 정렬되어 저장됩니다.
카산드라에서는 컬럼 또는 슈퍼컬럼의 이름을 어떻게 다룰것인지를 정의할 수 있습니다.(이름의 값은 단지 Byte Array로 저장됩니다만…) 이름은 Bytes Type, Long Type, Ascii Type, UTF8 Type, Lexical UUID Type, Time UUID Type 으로 다루어질 수 있습니다. 이제 설명은 최대한 많이 해본것 같으니 이해를 돕기 위해 간단한 트위터를 빗댄 예시를 보여드리도록 하겠습니다.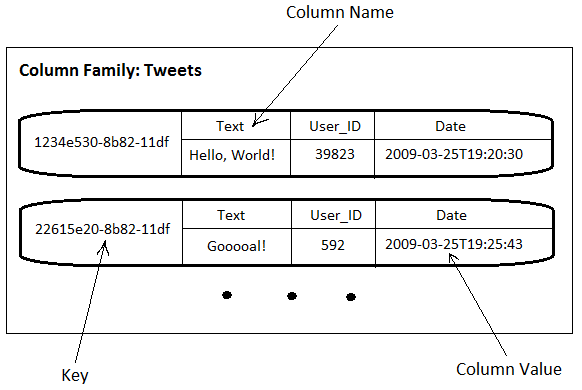 Tweets라는 컬럼 패밀리는 다음과 같은 트윗의 레코드를 가지고 있습니다. 레코드의 키는 Time UUID 타입이며 트윗을 받을때마다 생성됩니다. 하나의 레코드는 3개의 컬럼을 가지고 있으며(여기서 슈퍼컬럼은 사용하지 않습니다) 컬럼은 트윗에서 보여지는 간단한 내용을 입력해 보았습니다. 이러한 구조는 RDB에서 어떻게 데이터를 저장하는지와 비슷한 형태를 보여준다고 볼 수 있습니다.
Tweets라는 컬럼 패밀리는 다음과 같은 트윗의 레코드를 가지고 있습니다. 레코드의 키는 Time UUID 타입이며 트윗을 받을때마다 생성됩니다. 하나의 레코드는 3개의 컬럼을 가지고 있으며(여기서 슈퍼컬럼은 사용하지 않습니다) 컬럼은 트윗에서 보여지는 간단한 내용을 입력해 보았습니다. 이러한 구조는 RDB에서 어떻게 데이터를 저장하는지와 비슷한 형태를 보여준다고 볼 수 있습니다.
다음으로 보여드릴 예제는 User_Timelines(사용자가 직접 포스팅한 트윗들을 저장하는곳)입니다. 레코드의 키는 사용자의 ID입니다.(Tweets컬럼패밀리안의 User_ID컬럼의 값을 참조합니다) 아래의 예시는 컬럼의 이름이 어떻게 값으로써 사용되는지(트윗의 ID가 컬럼의 이름으로 사용되고 있습니다)를 보여줍니다. 여기서 중요한점은 여기서 사용되는 컬럼의 이름의 타입이 시간순으로 유니크한 값을 갖는 Time UUID라는 것입니다. 이것이 의미하는것은 글이 작성된 순서대로의 정렬이 계속해서 유지된다는것입니다. 이것은 사용자별로 가장 최근의 N개의 트윗을 보여주는데에 유용합니다. 각각의 값들은 사용할곳이 없으므로 빈값(여기서는 -로 표기)으로 저장합니다.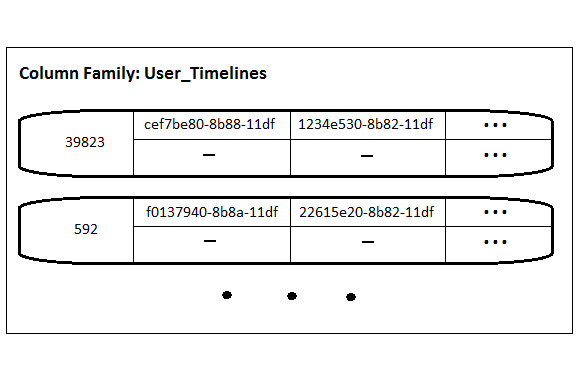
슈퍼컬럼에 설명드리기 위해서 트윗에 얼마나 많은 URL이 사용되었는지 통계를 내려고 한다는 가정을 가져보겠습니다. 트윗이 작성될 때 사용자는 URL을 포함할 수 있는데 특정 사용자가 특정 URL을 얼마나 많은 트윗에서 언급하였는지에 대한 통계를 슈퍼컬럼을 사용하여 낼 수 있습니다.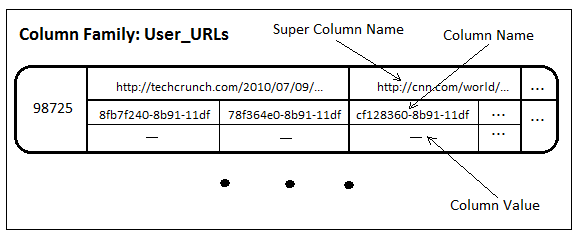 User_URLs컬럼패밀리에서는 URL들을 키로써 저장하고 내포하는 컬럼들은 이것을 언급한 트윗의 ID를 저장하고 있는것을 알 수 있습니다.
User_URLs컬럼패밀리에서는 URL들을 키로써 저장하고 내포하는 컬럼들은 이것을 언급한 트윗의 ID를 저장하고 있는것을 알 수 있습니다.
참고:
http://maxgrinev.com/2010/07/09/a-quick-introduction-to-the-cassandra-data-model/