이글은 Quora에 올라온 “What’s the difference between sharding and partition?“글의 질문과 모자이크 CTO가 답변한 내용을 번역한 글입니다.
샤딩(sharding)과 파티셔닝(partitioning)의 차이가 무엇인가?
분산 데이터베이스 시스템에서 샤딩과 파티셔닝이라는 단어를 종종 듣는다. 하지만 그들의 차이점을 잘 모르겠다. 그래서 이것들을 위키에서 검색해보았지만 여전히 혼란스럽다. 약간의 예제를 줄 수 있을까?
Tony Bako, Mosaic의 CTO의 답변
파티셔닝이란 퍼포먼스(performance), 가용성(availability) 또는 정비용이성(maintainability)를 목적으로 당신의 논리적인 데이터 엘리먼트들을 다수의 엔티티(table)로 쪼개는 행위를 뜻하는 일반적인 용어이다.
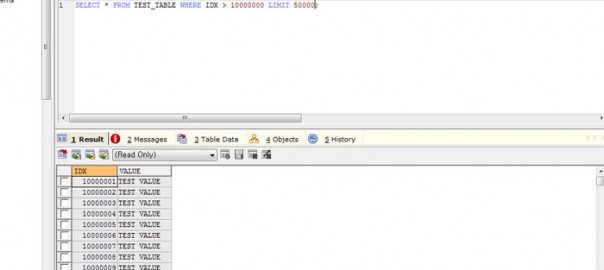
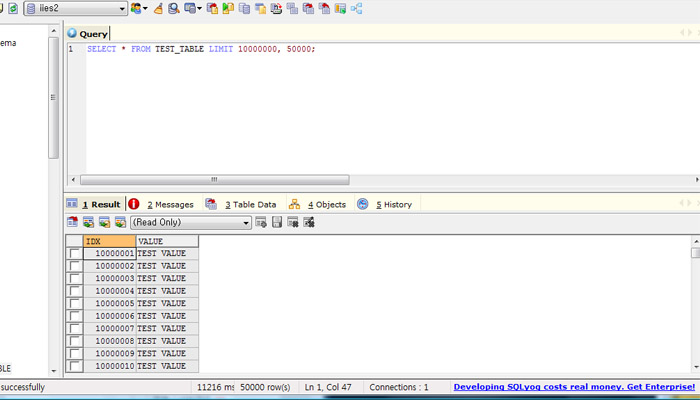
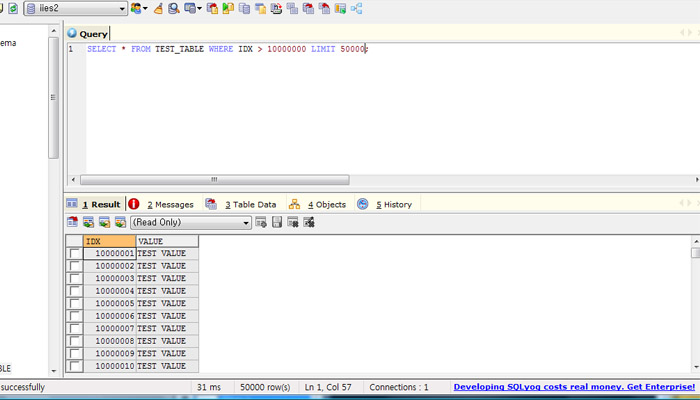
샤딩은 수평 파티셔닝(horizontal partitioning)과 동일하다. 데이터베이스를 샤딩하게 되면 기존에 하나로 구성될 스키마를 다수의 복제본으로 구성하고 각각의 샤드에 어떤 데이터가 저장될지를 샤드키를 기준으로 분리한다. 예를 들면, 나는 고객의 데이터베이스를 CustomerId를 샤드키로 사용하여 샤딩하기로 하였다. 0 ~ 10000 번 고객의 정보는 하나의 샤드에 저장하고 10001 ~ 20000 번 고객의 정보는 다른 샤드에 저장하기로 하였다. DBA는 데이터 엑세스 패턴과 저장 공간 이슈(로드의 적절한 분산 , 데이터의 균등한 저장)를 고려하여 적절한 샤드키를 결정하게 된다.
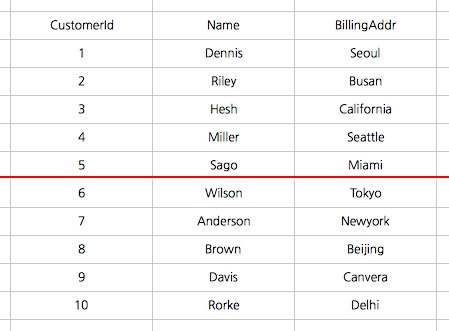
Horizontal Partitioning
수직 파티셔닝(vertical partitioning)은 하나의 엔티티에 저장된 데이터들을 다수의 엔티티들로 분리하는것을 말한다. (마찬가지로 공간이나 퍼포먼스의 이유로) 예를 들면, 한 고객은 하나의 청구 주소를 가지고 있을 수 있다. 그러나 나는 데이터의 유연성을 위해 다른 데이터베이스로 정보를 이동하거나 보안의 이슈등을 이유로 CustomerId를 참조하도록 하고 청구 주소 정보를 다른 테이블로 분리할 수 있다.
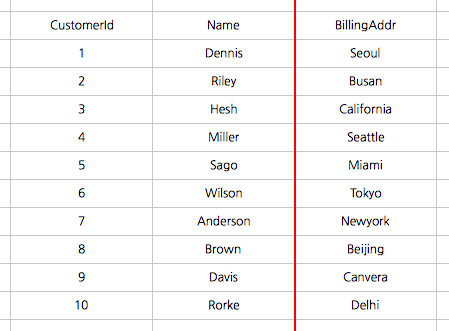
Vertical Partitioning
요약하면 파티셔닝은 퍼포먼스, 가용성, 정비용이성등의 목적을 위해 논리적인 엔티티들을 다른 물리적인 엔티티들로 나누는것을 의미하는 일반적인 용어이다. 수평 파티셔닝 또는 샤딩은 스키마 복제 후 샤드키를 기준으로 데이터를 나누는것을 말한다. 수직 파티셔닝은 스키마를 나누고 데이터가 따라 옮겨가는것을 말한다.