Maven은 매우 획기적인 방법의 라이브러리 관리툴인것 같습니다. 기존의 운영중인 프로젝트에 Maven을 도입하는 방법을 정리해 보겠습니다. 이 과정은 eclipse + m2eclipse 에서 이루어 졌으며 설치 및 세팅 방법은 [여기]에 정리해 두었습니다.
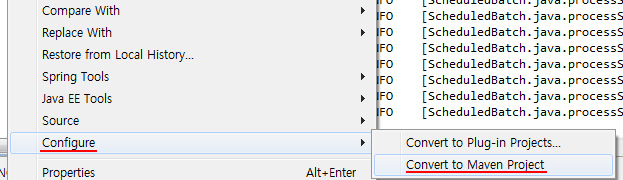
m2eclipse 플러그인이 정상적으로 설치가 되었다면 프로젝트를 선택하고 오른쪽 버튼을 클릭시에 위와 같이 Configure아래에 Convert to Maven Project가 있습니다.
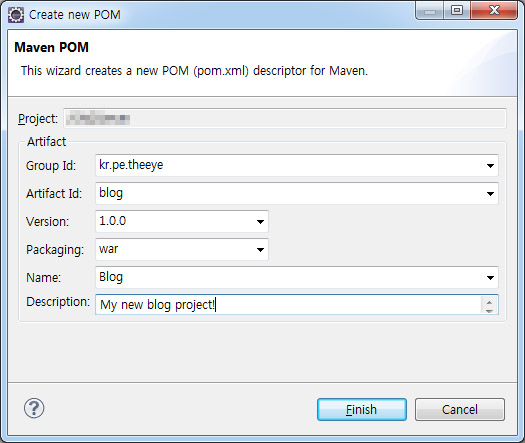
이것을 선택하면 위와 같이 POM.xml 파일을 만드는 과정이 나오는데요. Group Id는 프로젝트의 그룹의 식별자를 나타냅니다. 쉽게 생각해서 프로젝트의 패키지명을 생각하시면 될 것 같습니다. Artifact Id는 이 프로젝트를 나타내는 이름을 쓰시면 됩니다. 기존의 거의 대부분의 Maven Repository에 등록된 라이브러리들은 Group Id와 Artifact Id를 소문자와 대시(-) 구성하더군요. 편하신대로 하시면 됩니다.
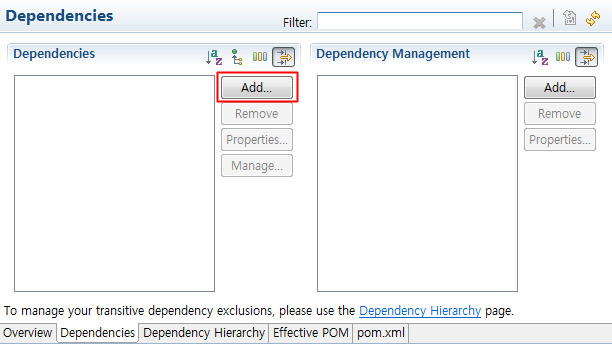
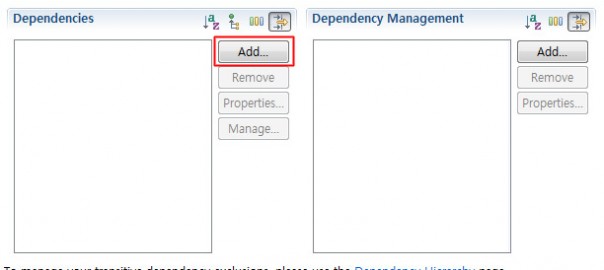
이제 POM.xml이 만들어 졌습니다. 이 파일을 더블클릭해서 열어보면 위와 같이 아름다운 설정 화면이 뜨게 되는데요. 라이브러리는 Dependencies 탭에서 추가를 하면 됩니다. Add를 눌러 라이브러리를 추가해 봅시다.
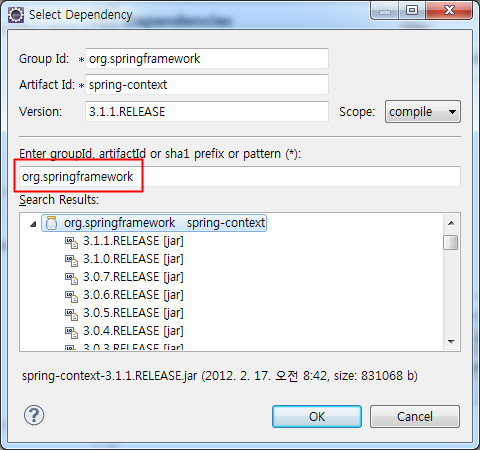
이것이야 말로 신기원! 빨간색 네모 박스 안에 검색 키워드를 넣게 되면 하단에 검색된 라이브러리들이 출력됩니다. 라이브러리앞의 삼각형을 누르면 버전 리스트들이 나오게 됩니다. 여기서 자신이 원하는 라이브러리와 버전을 선택하시면 됩니다.
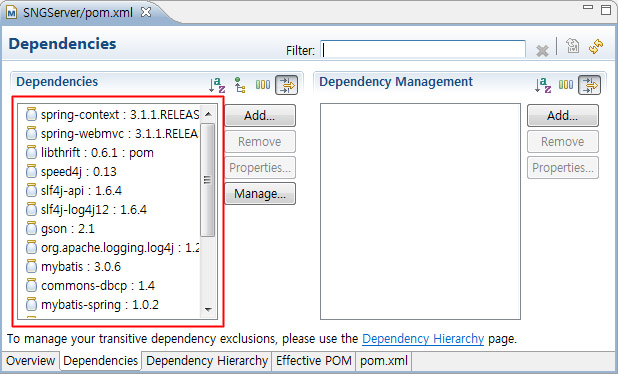
이런식으로 원하는 라이브러리를들을 추가해 주시면 알아서 필요한 의존성까지 체크하여 알아서 추가 등록까지 해줍니다. 정말 편하고 좋네요. 참고로 추가된 라이브러리가 제대로 등록되지 않는것 같아 보일때는 Project – Clean 한번 하시면 됩니다.
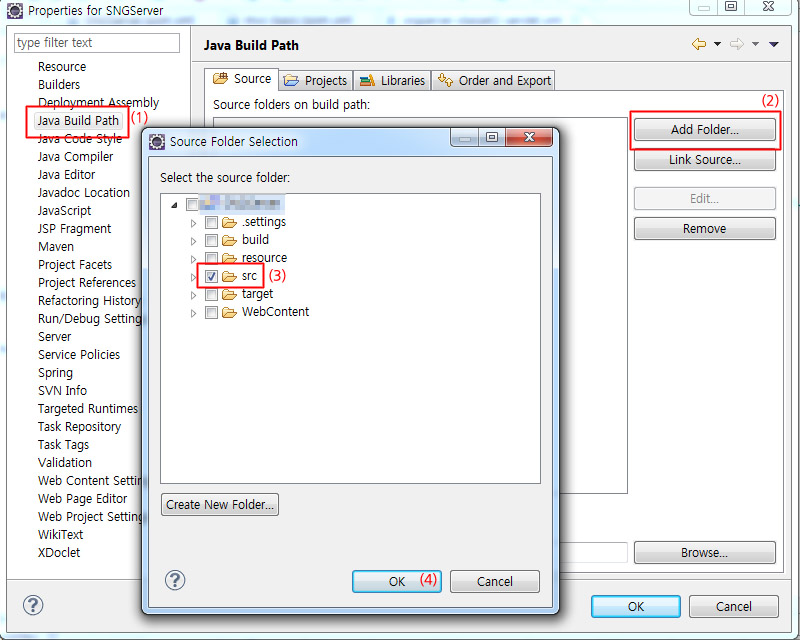
간혹 처음부터 Maven프로젝트로 시작하지 않고 중간에 변경할 경우 소스 디렉토리가 더이상 소스디렉토리로 인식되지 않는 경우가 있습니다. 이경우 프로젝트의 설정에 가서 src를 선택해 주시면 됩니다.
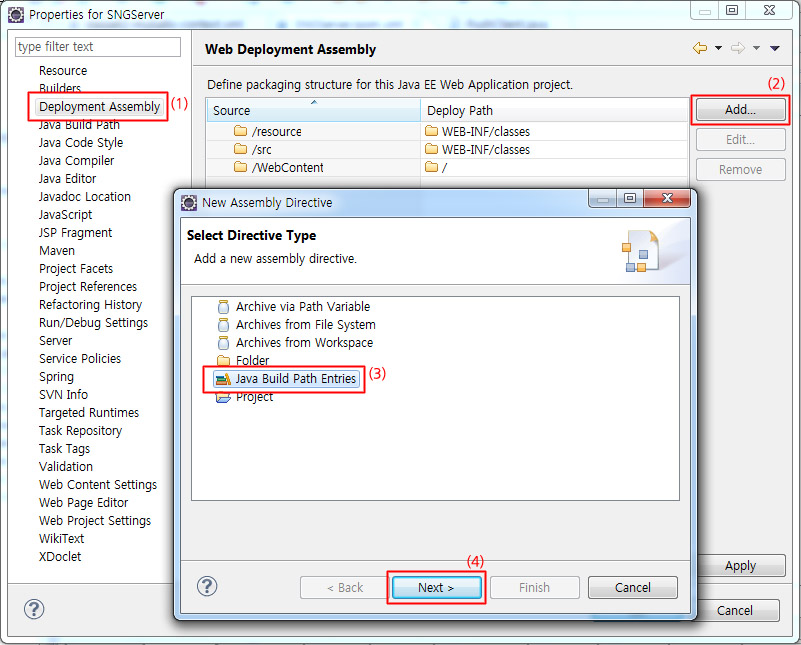
이제 해야 하는 설정은 필요한 경우에만 하면 되는 설정입니다. 디플로이시에 Maven에 추가한 라이브러리들이 빠지는 문제가 있는데요. 위와같이 프로젝트 설정에 가서 Next를 누르게 되면…
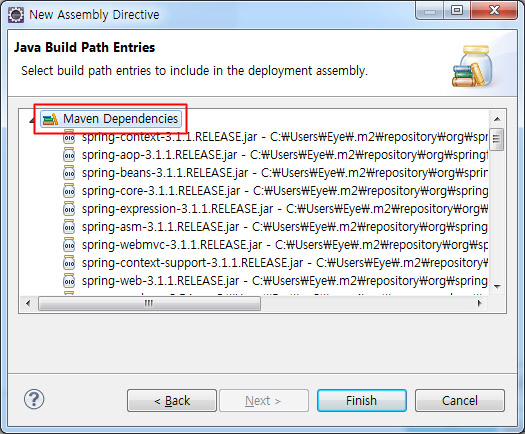
위와 같이 Maven Dependencies 가 나오게 되는데 선택해 주시면 Maven으로 추가한 라이브러리들도 Deploy 결과물에 포함되게 됩니다.
또 대단한게 Effective POM 탭에 가보시면 좀더 효율적으로 짜여진 POM파일의 예시를 보여줍니다. 이 탭을 참고하여 자신이 얼마나 효율적으로 Dependencies 설정을 하였는지 확인해 볼 수 있습니다.