
최근버전의 Cassandra에서는 Order Preserving Partitioner가 deprecated 되었지만 대체하기 위해 등장한 Byte Ordered Partitioner 역시 Order Preserving Partitioner와 같은 맥락이니 편하게 Order Preserving Partitioner를 가지고 설명을 해보도록 하겠습니다. 제가 타이핑 하기 좀 힘드니 지금부터는 RP(Random Partitioner)와 OPP(Order Preserving Partitoner)로 줄여서 부르도록 하겠습니다.
기본적인 개념
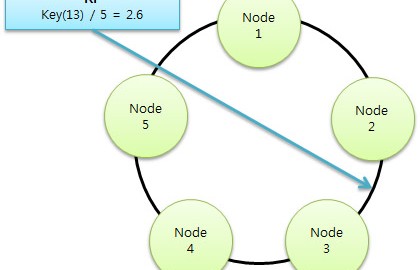
RP는 기본적으로 모든 노드가 균등한 데이터를 보유하는것을 목적으로 두고 있습니다. 그렇기 때문에 입력되는 데이터의 키를 MD5로 해싱하여 선택된 노드에 저장을 합니다. 결론적으로 사용자는 지금 입력하는 데이터가 정확히 어떤 노드들에 들어갈지 예측을 할 수 없습니다.
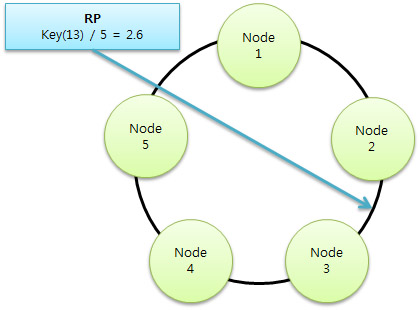
조금 단순화 시킨 예시입니다만(저렇게 단순히 나누기5로 결정하진 않겠지요) 해싱된 키로 저장될 노드를 결정합니다. 하지만 OPP는 키 자체가 노드를 뜻합니다. 이로써 얻는 이점은 원을 이루고 있는 클러스터의 노드들이 정확하게 정렬된 데이터를 가지고 있다는 것입니다.
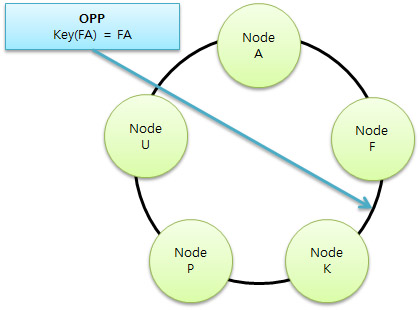
이번엔 이 예시를 보도록 할까요. 노드 F는 키가 A~F까지의 데이터를 가지고 있을것입니다. 노드 K는 키가 FA부터 K까지의 데이터를 가지고 있을것입니다. 즉 사용자가 보기에도 데이터가 어디에 들어갈지 노드들끼리도 이 데이터가 어디에 있을지 알 수 있습니다.
OPP를 사용함으로써 얻는 장점은 무엇인가
OPP를 사용함으로써 얻을 수 있는 장점은 키가 정렬이 된다는 것입니다. RP를 사용하게 되면 이상하게도 키가 정렬이 되는듯하면서 한두개씩 안되고 안드로메다로 떠나버리더군요. 이 말은 즉 Range Scan을 할 수 없다는것이 됩니다. 실제로 RP에서 다양한 방법으로 키를 기반으로 하는 Range Slice 쿼리를 날려보면 데이터가 뒤죽박죽으로 반환됩니다. RP에서는 키가 정렬을 지원하지 않는다고 생각하시면 됩니다. OPP는 키가 정렬이 됩니다.
OPP를 사용하게 되면 카산드라를 통해 풀텍스트 검색을 지원할 수 있게 됩니다. 실제로 Lucandra(현재는 Solandra로 변경)라는 Lucene의 카산드라 Integration 프로젝트를 보면 이러한 검색기능을 지원합니다. 이것은 즉 ‘아’로 검색을 하면 ‘아이’, ‘아이군’, ‘아이블로그’가 검색될 수 있음을 뜻합니다. RP기반에서는 상상도 못할 일입니다.
좀 더 나아가 특정 데이터가 잘못되었을 경우 전체 키를 스캔하여 잘못된 데이터를 찾아내어 수정할 한다거나 복구를 할 수 있습니다. RP기반에서는 어떤 키가 저장되어있는지 명확히 알아낸다는게 쉽지 않은 일입니다.
하지만 이렇게 좋기만한 OPP를 사용하길 권하지 않는 이유가 있습니다. 바로 로드 밸런싱의 문제가 있기 때문입니다.
OPP를 사용함으로써 발생하는 문제점은 무엇인가
RP의 경우에는 매번 새로운 노드를 추가할때마다 단순히 가장 많은 키들을 보관중인 노드의 데이터 절반을 띄어 가진후에 클러스터에 참여를 하는 단순한 방법을 취하면 됩니다. 이게 무슨말이냐면 RP에서는 모든 키를 무작정 MD5해시를 사용하여 키를 변환하며, 변환된 키가 실제 어떤 노드에 존재할지를 결정짓는 데이터의 주소가 됩니다. 실제 데이터가 다른 노드로 이사를 가더라도 클러스터안의 해싱된 로지컬한 주소는 결국 실제 데이터가 옮겨간 곳을 가리키게 됩니다.
하지만 OPP의 경우에는 단순하지 않습니다. 키 자체가 노드의 주소였기 무작정 스케일 아웃을 하다보면 때문에 엉뚱한 곳에서 데이터를 꺼내온다거나 시간 기반 데이터인 카산드라의 특성상 옛날 데이터를 꺼내올 수 있습니다. 한집에 사는 가족이 너무 많아져서 절반을 다른곳으로 이주시켰는데 자꾸만 이전집에서 사람을 찾는격이 될 수 있습니다.
OPP의 가장 큰 문제점은 로드 밸런싱 문제인데 키 자체가 노드를 결정짓기 때문에 예를 들어 A노드에 저장될 데이터를 계속 입력한다면 A의 부담이 커질 수밖에 없습니다. 이 말은 즉 특정 노드가 다른 노드에 비해 유난히 큰 데이터를 가지고 유난히 더 큰 부담을 가지게 됨을 의미합니다.
OPP를 사용하게 되면 스케일 아웃이 쉽지 않은 작업이 될것임에 분명해 보입니다. OPP를 굳이 사용하겠다면 데이터의 규모를 예측하여 적당히 큰 규모의 클러스터를 만들어 놓고 서비스를 시작하는것이 좋지 않을까 생각합니다.
참고 :
http://ria101.wordpress.com/2010/02/22/cassandra-randompartitioner-vs-orderpreservingpartitioner/
http://abel-perez.com/cassandra-partitioner-order-preserving-partit
http://www.slideshare.net/nzkoz/intro-to-cassandra-and-cassandraobject