
요즘 많은 관심을 받고 있는 NoSQL의 대표주자인 Cassandra의 경우에는 Digg, Facebook, Twitter등에서 사용이 되며 충분히 많은 관심을 받고 있는 대표적인 데이터베이스(?) 시스템입니다. 카산드라는 아마존의 Dynamo와 구글의 BigTable로부터 파생되었습니다. 카산드라는 일반적인 Key/Value 시스템들보다 훨씬 멋진 컬럼패밀리(ColumnFamily) 기반의 시스템을 제공합니다.
카산드라는 기존의 SQL시스템과 비교할때 다음의 3가지 장점을 제공합니다.
– 매우 단순한 캐패시티(Capacity) 확장
무한히 확장하는 부하가 가해질 경우 기존의 MySQL시스템에서도 충분히 이러한 부하를 처리할 수 있습니다. 이미 오랜 기간동안 증명이 된 부분이죠. 하지만 문제는 이것이 쉽지가 않다는 것입니다. 기존의 SQL시스템(RDBMS)에서는 관계(Relational)라는 것이 이러한 문제점을 더욱 키우게 됩니다. 예를 든다면 JOIN이라는 무서운 적이 있겠네요.
하지만 카산드라에서는 몇분의 시간을 할애하여 새로운 노드를 추가함으로써 말 그대로의 캐패시티 확장을 이룰 수 있습니다. 새로운 노드를 추가하고 DNS에 라운드로빈(Round-Robin)방식으로 로드밸런싱을 하는것만으로도 시스템을 확장할 수 있습니다. 물론 다른 다양한 로드밸런싱 처리도 가능하겠죠.
– 고정된 스키마
SQL을 이용한 프로젝트를 수행할경우에는 각 테이블의 스키마를 정의하여야 합니다. 그리고 프로젝트가 진행이 되어갈수록 새로운 필드를 추가하게 됩니다. 이 과정을 거치게 되면서 데이터 스키마는 변동을 가지게 되고 개발중인 어플리케이션 역시 기존의 데이터 처리를 하던 부분에 예외처리를 하던지 상호 호환성을 가지도록 다시한번 시간을 투자해 프로그램을 수정해야 합니다. 프로그램의 버전마다 테이블 스키마가 달라진다면 이것 역시 큰 문제가 될 수 있습니다.
카산드라는 일명 스키마리스(Schema-less)입니다. 스키마가 필요없다는 뜻이죠. 새로운 필드를 추가하고 싶다면 단지 추가하면 됩니다. 다른 데이터에 미치는 영향은 전혀 없습니다. 이것은 개발 시간을 단축시켜줍니다. 하지만 프로젝트가 좀 더 복잡해 질수는 있습니다.
– 처리량
SQL에서는 원하는 데이터를 추출하고 보여주는 다양한 방식을 제공합니다. 예를 들면 조인(JOIN), 서브쿼리(SUBQUERY)와 같은 다양한 방법을 이용할 수 있습니다. 하지만 이와 같은 데이터 조합 방법은 같은 데이터를 계속해서 요청하고 처리한다는 단점을 가지고 있습니다. 또한 SQL에서는 이 경우에 테이블 혹은 로우(Row)를 Lock을 걸기 때문에 동시 처리능력이 떨어지는 단점이 있습니다. 또한 수많은 사용자가 동시에 이러한 처리를 요청한다면 저 수많은 데이터의 재처리가 더욱 많이 발생할 것입니다.
카산드라는 이와같은 데이터 모델과는 크게 다릅니다. 말이 어렵겠지만 그냥 데이터를 있는 그대로 사용하면 됩니다. 카산드라와 PHP를 함께 사용하기 위한 라이브러리는 여러가지가 있습니다. 그중에서도 특히 phpcassa를 추천합니다.
1. thrift PHP Native 설치하기
thrift는 Facebook에서 만든 멀티플랫폼 환경에서 사용할 수 있는 Cassandra를 사용하기 위해 설치되어야 하는 플랫폼입니다. 기본적으로 대부분의 모든 언어에서 사용할 수 있는 라이브러리셋을 제공합니다. 하지만 좀더 빠르게 사용하기 위해서는 PHP의 Native 모듈로 설치하는 것을 추천합니다. [이곳]에서 thrift를 다운받도록 합니다.
[code]cd thrift/ext/thrift_protocol
phpize
./configure
make
sudo make install[/code]
위와 같이 컴파일 하여 설치한후에 /etc/php.d/thrift_protocol.ini 와 같이 php설정파일을 추가합니다.
[code]extension=thrift_protocol.so[/code]
혹시 위의 경로에 소스가 없을 경우 lib/php/src/ext/thrift_protocol 을 참고하시기 바랍니다.
2. phpcassa 사용하기
[이곳]에서 전체 소스를 다운받습니다. 받은 파일을 프로젝트 폴더의 phpcassa디렉토리로 옮겨놓습니다. 이제 프로젝트 소스파일의 상단에 다음과 같은 코드를 추가하면 Cassandra서버에 접속할 수 있게 됩니다.
[code]require_once(‘phpcassa/connection.php’);
require_once(‘phpcassa/columnfamily.php’);[/code]
– 커넥션 연결
phpcassa가 현재 실행중인 카산드라의 연결 인스턴스를 만들기 위해서는 다음의 과정이 필요합니다.
[code]$conn = new Connection(‘Keyspace’);[/code]
위의 코드는 디폴트로 설정된 호스트와 포트를 사용합니다. 물론 이 호스트와 포트를 특정지을수도 있습니다.
[code]$conn = new Connection(‘Keyspace1’, array(array(‘host’ => localhost, ‘port’ => 9160)));[/code]
– 컬럼패밀리 가져오기
카산드라에서 컬럼패밀리는 로우(Row)나 컬럼(Column)의 집합입니다. 이것은 RDB에서의 테이블과 비슷한 역할을 합니다. 스키마로 이미 지정된 하나의 컬럼 패밀리를 가져오는 방법은 다음과 같습니다.
[code]$column_family = new ColumnFamily($conn, ‘Standard1’);[/code]
– 데이터 삽입
컬럼패밀리에 하나의 로우를 입력하기 위해서는 다음과 같은 메서드를 사용하면 됩니다.
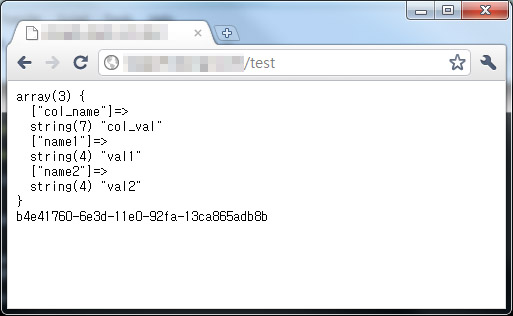
[code]$column_family->insert(‘row_key’, array(‘col_name’ => ‘col_val’));[/code]
위와 같이 한번에 하나씩 데이터를 입력하는 방법말고도 한번에 한개이상의 컬럼을 삽입하는 것도 가능합니다.
[code]$column_family->insert(‘row_key’, array(‘name1’ => ‘val1’, ‘name2’ => ‘val2’));[/code]
– 데이터 가져오기
카산드라에서 데이터를 가져오는 방법은 데이터를 삽입할때보다 훨씬 많은 방법을 제공합니다.
[code]$column_family->get(‘row_key’);
// returns: array(‘colname’ => ‘col_val’)[/code]
위의 메서드는 하나의 키에 대한 컬럼값을 가져오게 됩니다. 추가적인 인자 없이 메서드를 실행할 경우 로우안의 모든 컬럼데이터를 가져오게 됩니다($column_count만큼, 기본값은 100). 만약에 이름을 알고 있는 특정 컬럼만을 데이터로 가져오고 싶다면 $columns 인자를 사용하면 됩니다.
[code]$column_family->get(‘row_key’, $columns=array(‘name1’, ‘name2’));
// returns: array(‘name1’ => ‘foo’, ‘name2’ => ‘bar’)[/code]
로우의 컬럼들의 일부분만을 가져오기 위해서는 $column_start와 $column_finish 파라미터를 사용하면 됩니다. 둘중에 하나 또는 둘다의 값을 빈값으로 사용할 수 있습니다. 이경우 $column_finish는 꼭 설정해주어야 합니다. 컬럼의 이름이 1부터 9까지 있다고 가정할 때 다음과 같이 사용할 수 있습니다.
[code]$column_family->get(‘row_key’, $columns=null, $column_start=’5′, $column_finish=’7′);
// returns: array(‘5’ => ‘foo’, ‘6’ => ‘bar’, ‘7’ => ‘baz’)[/code]
한번에 다수의 로우를 가져오기 위해서는 다음과 같은 방법을 사용하면 됩니다.
[code]$column_family->multiget([‘row_key1’, ‘row_key2’]);
// returns: array(‘row_key1’ => array(‘name’ => ‘val’), ‘row_key2’ => array(‘name’ => ‘val’))[/code]
키를 이용한 특정 범위의 로우를 한번에 가져오기 위한 방법으로는 다음과 같은 방법이 있습니다. 이경우에도 $key_finish는 꼭 설정하여야 합니다. ‘row_key1’부터 ‘row_key9’까지의 로우가 존재하고 있다고 가정할 경우 다음과 같은 방법을 사용할 수 있습니다.
[code]$rows = $column_family->get_range($key_start=’row_key5′, $key_finish=’row_key7′);
// returns an Iterator over:
// array(‘row_key5’ => array(‘name’ => ‘val’),
// ‘row_key6’ => array(‘name’ => ‘val’),
// ‘row_key7’ => array(‘name’ => ‘val’))
foreach($rows as $key => $columns) {
// Do stuff with $key or $columns
print_r($columns);
}[/code]
– 카운팅(Counting)
특정 로우의 컬럼이 얼마나 많이 있는지 알아내기 위해서는 다음과 같은 방법을 사용합니다.
[code]$column_family->get_count(‘row_key’);
// returns: 3[/code]
키뿐만 아니라 컬럼의 이름을 정확히 알고 있을 경우 특정 범위만큼의 컬럼의 수를 알아내는것도 가능합니다.
[code]$column_family->get_count(‘row_key’, $columns=array(‘foo’, ‘bar’));
// returns: 2
$column_family->get_count(‘row_key’, $column_start=’foo’);
// returns: 3[/code]
또한 다수의 로우의 컬럼 숫자를 병렬로 알아오는 것도 가능합니다.
[code]$column_family->multiget_count(array(‘fib0’, ‘fib1’, ‘fib2’, ‘fib3’, ‘fib4’));
// returns: array(‘fib0’ => 1, ‘fib1’ => 1, ‘fib2’ => 2, ‘fib3’ => 3, ‘fib4’ => 5)
$column_family->multiget_count(array(‘fib0’, ‘fib1’, ‘fib2’, ‘fib3’, ‘fib4’),
$columns=array(‘col1’, ‘col2’, ‘col3’));
// returns: array(‘fib0’ => 1, ‘fib1’ => 1, ‘fib2’ => 2, ‘fib3’ => 3, ‘fib4’ => 3)
$column_family->multiget_count(array(‘fib0’, ‘fib1’, ‘fib2’, ‘fib3’, ‘fib4’),
$columns=null, $column_start=’col1′, $column_finish=’col3′)
// returns: array(‘fib0’ => 1, ‘fib1’ => 1, ‘fib2’ => 2, ‘fib3’ => 3, ‘fib4’ => 3)[/code]
– 슈퍼 컬럼(Super Columns)
카산드라는 컬럼의 그룹격인 일명 슈퍼컬럼을 제공합니다. conf/schema-sample.txt 파일의 내용을 보면 다음과 같은 설정을 확인할 수 있습니다.
– name: Super1
column_type: Super
phpcassa에서 슈퍼컬럼을 사용하기 위해서는 추가적인 레벨의 배열의 사용하면 됩니다.
[code]$column_family = new ColumnFamily($conn, ‘Super1’);
$column_family->insert(‘row_key’, array(‘supercol_name’ => array(‘col_name’ => ‘col_val’)));
$column_family->get(‘row_key’);
// returns: array(‘supercol_name’ => (‘col_name’ => ‘col_val’))[/code]
– 컬럼의 이름과 값의 타입
현재의 최신버전인 카산드라 0.7에서는 컬럼 이름을 위한 Comparator Type과 컬럼의 값의 Validator Type을 설정할 수 있습니다. 다음과 같은 타입을 사용할 수 있습니다.
BytesType – no type
IntegerType – 32 bit integer
LongType – 64 bit integer
AsciiType – ASCII string
UTF8Type – UTF8 encoded string
TimeUUIDType – version 1 UUID (timestamp based)
LexicalUUID – non-version 1 UUID
컬럼이름의 Comparator 타입의 설정은 컬럼이 어떻게 정렬될 것인지에 대해 영향을 끼칩니다. 위에서 일반적인 컬럼패밀리와 슈퍼컬럼패밀리에 대해서 알 수 있었습니다. 슈퍼컬럼패밀리에서의 경우에는 하위컬럼들에도 별도로 다른 Comparator 타입을 지정할 수 있습니다.
– name: StandardInt
column_type: Standard
compare_with: IntegerType
– name: SuperLongSubAscii
column_type: Super
compare_with: LongType
compare_subcolumns_with: AsciiType
카산드라는 위와 같은 타입들에 대해 바이너리 형태로서 이해를 합니다. 하지만 phpcassa에서는 이러한 데이터 타입의 Pack/Unpack을 자동으로 지원합니다. 결과적으로 다음과 같은 방법으로 IntegerType의 컬럼을 자유롭게 추가할 수 있습니다.
[code]$column_family = new ColumnFamily($conn, ‘StandardInt’);
$column_family->insert(‘row_key’, array(42 => ‘some_val’));
$column_family->get(‘row_key’)
// returns: array(42 => ‘some_val’)[/code]
위에서 언급했듯이 카산드라는 컬럼의 값에 대한 Validator를 제공합니다. 이러한 Validator는 완전한 컬럼패밀리에 설정될 수 있으며 개별의 컬럼에 설정될수도 있습니다. 다음의 다양한 예시를 보시는것이 도움이 될 것 같습니다.
– name: AllLongs
column_type: Standard
default_validation_class: LongType
– name: OneUUID
column_type: Standard
column_metadata:
– name: uuid
validator_class: TimeUUIDType
– name: LongsExceptUUID
column_type: Standard
default_validation_class: LongType
column_metadata:
– name: uuid
validator_class: TimeUUIDType
phpcassa는 이러한 컬럼들의 자동적인 Pack역시 지원합니다.
[code]$column_family = new ColumnFamily($connection, ‘LongsExceptUUID’)
$column_family->insert(‘row_key’, array(‘foo’ => 123456789, ‘uuid’ => CassandraUtil::uuid1()));
$column_family->get(‘row_key’);
// returns: array(‘foo’ => 123456789, ‘uuid’ => UUID(‘5880c4b8-bd1a-11df-bbe1-00234d21610a’))[/code]
위와같은 자동화된 Pack/Unpack이 불필요할 경우 다음과 같은 방법으로 설정을 끌 수도 있습니다.
[code]$column_family = new ColumnFamily($conn, ‘Standard1’,
$autopack_names=False,
$autopack_values=False);[/code]
– 인덱스
카산드라 0.7부터는 2차 인덱스기능을 제공합니다. 이것을 이용하면 특정한 표현식을 사용하여 원하는 데이터만을 가져오는 방법을 매우 효율적으로 사용할 수 있습니다.
– name: Indexed1
column_type: Standard
column_metadata:
– name: birthdate
validator_class: LongType
index_type: KEYS
다음의 예시는 인덱스가 걸려있는 birthdate컬럼의 값이 1984인 로우를 가져옵니다.
[code]$column_family = new ColumnFamily($conn, ‘Indexed1’);
$index_exp = CassandraUtil::create_index_expression(‘birthdate’, 1984);
$index_clause = CassandraUtil::create_index_clause(array($index_exp));
$rows = $column_family->get_indexed_slices($index_clause);
// returns an Iterator over:
// array(‘winston smith’ => array(‘birthdate’ => 1984))
foreach($rows as $key => $columns) {
// Do stuff with $key and $columns
print_r($columns)
}[/code]
참고:
http://thobbs.github.com/phpcassa/tutorial.html
http://blog.nowvu.com/2010/08/19/cassandra-and-php-become-friendly-with-phpcassa/



 참고:
참고: