iBATIS와 OSCache를 연동하는 방법은 많이 볼 수 있습니다. 특히 다수의 서버가 캐시 데이터를 연동하는 클러스터링에 대해 알아보려면 [이곳]을 참고하면 JMS와 JavaGroups를 이용한 클러스터링을 소개하고 있는 것을 알 수 있습니다.
하지만 좀 다르게 저는 NFS + Persistence설정을 사용하여 클러스터링을 구현해 보도록 하겠습니다. 이경우 얻을 수 있는 이득으로는 캐시를 디스크에 하기 때문에 서버의 작동여부와 상관없이 장기간의 캐시데이터를 유지할 수 있습니다. 예를 들면 홈페이지 첫화면의 공지사항이 한달에 1~2번 올라오는 경우라면 이렇게 캐시를 구성하면 매일 서버를 껐다키더라도 공지사항의 캐시를 유지할 수 있습니다.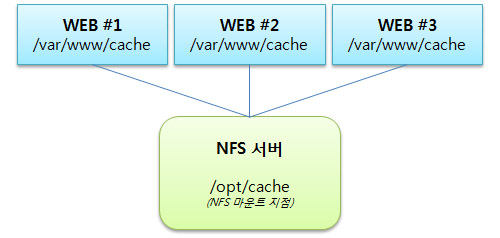
* 준비사항
우선 iBATIS 최신버젼과 OSCache 최신버젼을 받도록 합시다. 저의 경우에는 iBATIS이전 버젼으로 시도했을때 알 수 없는 Exception이 발생하는 문제가 있었습니다. 추가적으로 CGLIB, COMMONS-DBCP, COMMONS-LOGGING, LOG4J jar가 필요합니다.
iBATIS의 경우 약간의 소스 수정이 필요합니다. 우선 뒤쪽에서 언급할 소스수정 단계를 거쳤다고 생각하고 필요한 jar파일들을 프로젝트의 Lib디렉토리에 넣습니다. 추가로 OSCache의 etc폴더 안에 있는 oscache.properties 파일을 프로젝트의 classes디렉토리 루트에 넣으시면 됩니다. 꼭 여기만 되더군요. 이클립스를 사용하실 경우 마우스 오른쪽 클릭하시고 move를 이용하셔서 넣으시면 편합니다.
* OSCache 설정 변경
oscache.properties 파일의 내용을 다음과 같이 변경합니다. 아래에 언급되지 않은 설정의 경우 모두 디폴트(주석처리)로 설정함을 의미합니다.
[code]cache.memory=false
cache.persistence.class=
com.opensymphony.oscache.plugins.diskpersistence.HashDiskPersistenceListener
cache.path=d:\\tmp\\cache
cache.algorithm=com.opensymphony.oscache.base.algorithm.UnlimitedCache
cache.unlimited.disk=true[/code]
위에서 cache.path의 경우 윈도우는 \\로 유닉스 계열에서는 /로 디렉토리 경로를 표시합니다.
* iBATIS 설정 변경
sql-map-config에 다음과 같은 캐시모델에 대한 설정을 합니다. 이외의 설정의 경우 기존에 사용하시던데로 사용하시면 됩니다.
[code]<settings
useStatementNamespaces=”true”
cacheModelsEnabled=”true”
classInfoCacheEnabled=”true”
/>[/code]
* SQL MAP에 캐시 설정
캐시 모델이라는 개념을 사용하여 캐시를 하고 만들어진 캐시를 삭제하는 작업을 하게 됩니다.
[code]<cacheModel type=”OSCACHE” id=”cacheModel” readOnly=”true”>
<flushInterval hours=”24″/>
<flushOnExecute statement=”flushCache”/>
</cacheModel>
<resultMap class=”kr.pe.theeye.Cache” id=”CacheResult”>
…
</resultMap>
<insert id=”flushCache” resultClass=”string”>
INSERT …
</insert>
<select id=”makeCache” resultMap=”CacheResult” cacheModel=”cacheModel”>
SELECT …
</select>[/code]
위의 예제에 대해 설명을 해보자면 CacheModel에서 각각의 캐시 설정을 하게 됩니다. type에는 OSCACHE를 넣어주시고 id에 식별자를 넣어줍니다. 그리고 ReadOnly설정을 하게 되면 수정을 하지 않는다는 것으로 약간의 퍼포먼스 향상을 꾀할 수 있습니다.
하위의 설정으로는 대표적으로 flushInterval설정이 있는데 시, 분, 초, 밀리초 단위의 설정을 할 수 있습니다. flushOnExecute의 경우에는 어떤 쿼리가 실행될 때 이 캐시를 삭제하면 되는지를 넣어주시면 됩니다. 다수의 설정이 가능합니다.
resultMap의 경우에는 잘 아시겠지만 추가적으로 알아두셔야 할 점이 여기에 사용되는 클래스는 꼭 Serializable 인터페이스를 구현하고 있어야합니다. 파일로 쓰기 때문에 중요합니다. 안해두시면 에러납니다.
다음의 insert 쿼리의 id가 아까 캐시모델의 flushOnExecute에 정의되어있는 식별자인것을 알 수 있습니다. 이 쿼리가 실행될때마다 만들어진 캐시를 삭제하게 됩니다. 보통 CRUD에서 CUD에 해당하는 작업을 모두 정의해 주시면 될 것 같습니다.
마지막으로 중요한 select문입니다. cacheModel이라는 설정에서 어떤 캐시모델을 사용할 것인지 식별자를 넣어주시면 됩니다. 이제 이 쿼리가 수행될때 마다 캐시가 존재하면 데이터베이스 서버를 거치지 않고 캐시된 결과를 반환하고 캐시가 없을 경우 데이터베이스에 쿼리를 날리고 결과를 반환함과 동시에 캐시하게 됩니다.
* iBATIS 소스 수정
여기까지 해보고 클러스터링을 테스트 해보게 되면 전혀 클러스터링이 되지 않음을 알 수 있습니다. 캐시를 저장할 때 사용하는 해시키값이 객체를 해시하는등의 복잡한 과정을 거치며 값이 머신마다 달라짐에 따라 다른 캐시로 인지하게 되는 문제입니다. 이것을 단순히 쿼리문과 그의 인자값만으로 캐시키로 사용하도록 바꾸어 보겠습니다.
1. 다운받은 iBATIS의 src폴더에 들어가면 ibatis-src.zip파일이 있는데 압축을 푼다.
2. src\ibatis-src\com\ibatis\sqlmap\engine\cache\CacheKey.java 파일을 iBATIS의 lib폴더로 옮긴다.
3. CacheKey.java 의 toString()메서드를 수정합니다.
[code]public String toString() {
/*
StringBuffer returnValue = new StringBuffer().append(hashcode).append(‘|’).append(checksum);
for (int i=0; i < paramList.size(); i++) {
returnValue.append(‘|’).append(paramList.get(i));
}
return returnValue.toString();
*/
int index = paramList.size()-3;
StringBuffer returnValue = new StringBuffer();
returnValue.append(paramList.get(index));
returnValue.append(paramList.get(–index));
for (int i=index-2; i > -1; i–) {
returnValue.append(‘|’).append(paramList.get(i));
}
return returnValue.toString();
}[/code]
4. lib폴더에 있는 ibaris-버젼.jar파일을 jar -xvf <파일명>으로 압축을 해제 합니다.
5. lib폴더 안에서 다음의 명령을 수행하여 CacheKey.java파일을 컴파일 합니다.
[code]javac -classpath . -d ./ CacheKey.java[/code]
6. 컴파일 된 CacheKey.class파일을 원래의 위치로 옮겨 옮깁니다.
7. jar -cvf ibatis.jar * 명령을 사용하여 다시 압축합니다.
8. 만들어진 jar 파일을 사용합니다.
* log4j 로그 확인
log4j.properties파일에 다음을 한줄 추가하면 로그를 확인할 수 있습니다.
[code]log4j.logger.com.opensymphony.oscache=DEBUG[/code]
* 결론
이제 모든 머신에서 동일하게 만들어질 키를 가지고 캐시를 식별하게 됩니다. 이것으로 모든 캐시를 영구적으로 보존할 수 있게 되었습니다. 관련되는 문제가 있을 것으로 생각되지만 간단한 테스트 결과 별 문제가 없지 않을까 생각됩니다. 보시고 예상되는 문제가 보이시면 적극 알려주시면 개선해보도록 하겠습니다.