지금까지 카산드라에 대해 글을 꽤나 쓴것 같네요. 이제부턴 몽고디비를 주제로 글을 써봐야 할것 같습니다. 아무튼 각설하고 이번에는 여러 노드로 구성된 클러스터를 구성하는 과정을 정리해 보도록 하겠습니다.
지금까지 카산드라에 대해 글을 꽤나 쓴것 같네요. 이제부턴 몽고디비를 주제로 글을 써봐야 할것 같습니다. 아무튼 각설하고 이번에는 여러 노드로 구성된 클러스터를 구성하는 과정을 정리해 보도록 하겠습니다.
싱글 노드 구성하기
카산드라는 기본적으로 여러대의 노드가 하나의 클러스터를 이루어 동작하는것을 목적으로 만들어졌습니다. 그러나 테스트 또는 체험용의 목적을 위하여 싱글 노드를 구성할 수 있습니다. 지금부터 단일 노드 구성을 시작해 보겠습니다.
1. cassandra.yaml 파일에 다음과 같은 설정을 하여줍니다.
[code]cluster_name: ‘MyClusterName’
initial_token: 0[/code]
2. 위의 설정만으로도 단일 노드 운영에는 문제가 없습니다, 하지만 이후에 지속적으로 노드를 확장해 나갈 예정이라면 다음의 설정을 처음 노드 설정시에 정확하게 해주는 것을 추천합니다. endpoint_snitch설정의 경우에는 기본적으로 SimpleSnitch를 사용하여도 무방합니다만 다음의 두가지를 추천합니다.
[code]seeds: <노드의 IP>
listen_address: <노드의 IP>
rpc_address: 0.0.0.0
endpoint_snitch: RackInferringSnitch | PropertyFileSnitch[/code]
3. 카산드라를 시작합니다. 데비안 패키지 혹은 RPM으로 설치하였다면 다음의 명령을 이용하여 서비스로 구동할수도 있습니다.
[code]# service cassandra start[/code]
일반적인 tar파일로 다운받아 설치하였다면 다음과 같이 직접 실행을 해주시면 됩니다.
[code]$ cd $CASSANDRA_HOME
sh bin/cassandra[/code]
다중 노드 구성하기
정확하게 다중 노드로 구성된 클러스터를 만들기 위하여 다음의 정보를 명확히 정의해 두어야 합니다.
* 클러스터의 이름
* 클러스터를 몇개의 노드로 구성할 것인가
* 각 노드들의 아이피 주소
* 각각의 노드들의 토큰 (뒤에 설명하겠습니다)
* 어떤 노드를 시드 노드로 정의할 것인가? 시드리스트는 리플리케이션그룹당 1개정도면 됩니다.
* 노드들간의 데이터 통신 플랜 설정인 snitch 선택
예를 들어 같은 데이터센터에 6개의 노드로 구성된 클러스터가 있다고 가정해 보겠습니다. 그런데 2개의 랙을 사용하며 3개의 노드가 각각 설치 되어있습니다. 이경우 랙당 하나의 노드를 seed 노드로 정의해 주시면 됩니다.
node0 110.82.155.0 (seed1)
node1 110.82.155.1
node2 110.82.155.2
node3 110.82.156.3 (seed2)
node4 110.82.156.4
node5 110.82.156.5
위와 같이 노드가 정의되어있다고 가정할때 각각의 노드의 cassandra.yaml 설정은 다음과 같습니다. 여기서 사용하는 snitch 설정인 RackInferringSnitch는 노드의 IP주소를 참고하는 플랜입니다. IP주소의 두번째, 세번째 값을 이용하여 같은 그룹임을 자동 인식합니다.
node0
[code]cluster_name: ‘MyDemoCluster’
initial_token: 0
seed_provider:
– seeds: “110.82.155.0,110.82.155.3”
listen_address: 110.82.155.0
rpc_address: 0.0.0.0
endpoint_snitch: RackInferringSnitch[/code]
node1
[code]cluster_name: ‘MyDemoCluster’
initial_token: 28356863910078205288614550619314017621
seed_provider:
– seeds: “110.82.155.0,110.82.155.3”
listen_address: 110.82.155.1
rpc_address: 0.0.0.0
endpoint_snitch: RackInferringSnitch[/code]
node2
[code]cluster_name: ‘MyDemoCluster’
initial_token: 56713727820156410577229101238628035242
seed_provider:
– seeds: “110.82.155.0,110.82.155.3”
listen_address: 110.82.155.2
rpc_address: 0.0.0.0
endpoint_snitch: RackInferringSnitch[/code]
node3
[code]cluster_name: ‘MyDemoCluster’
initial_token: 85070591730234615865843651857942052864
seed_provider:
– seeds: “110.82.155.0,110.82.155.3”
listen_address: 110.82.155.3
rpc_address: 0.0.0.0
endpoint_snitch: RackInferringSnitch[/code]
node4
[code]cluster_name: ‘MyDemoCluster’
initial_token: 113427455640312821154458202477256070485
seed_provider:
– seeds: “110.82.155.0,110.82.155.3”
listen_address: 110.82.155.4
rpc_address: 0.0.0.0
endpoint_snitch: RackInferringSnitch[/code]
node5
[code]cluster_name: ‘MyDemoCluster’
initial_token: 141784319550391026443072753096570088106
seed_provider:
– seeds: “110.82.155.0,110.82.155.3”
listen_address: 110.82.155.5
rpc_address: 0.0.0.0
endpoint_snitch: RackInferringSnitch[/code]
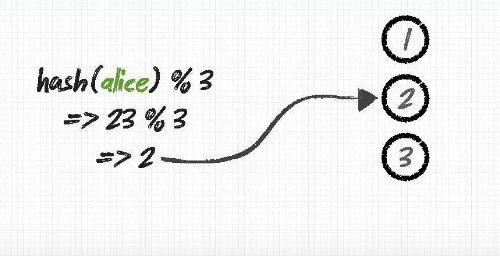
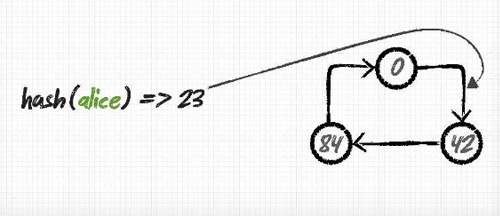
토큰 계산하기
토큰이란 특정 노드에 부여되는 데이터의 범위를 정의하는 값입니다. 기본값인 RandomPartitioner를 사용할 경우 다음의 내용을 참고하시어 모든 노드가 공평한(?) 데이터 분배를 받도록 할 수 있습니다. 이것이 이루어지지 않을 경우 특정 노드에만 부하가 가중된다거나 하는 클러스터상에 안좋은 영향을 끼치는 문제를 일으키는 원인이 될 수 있습니다.
각각의 노드에 토큰을 부여할때는 cassandra.yaml 파일의 initial_token에 값을 정의하여 주시면 되고 노드가 처음 시작 될때 정의 되어있어야 합니다.
1. 토큰 생성을 위한 프로그램을 제작하여 봅시다.
[code]vi tokengentool[/code]
2. 다음의 파이썬(Python) 프로그램을 붙여넣기 합니다.
[code]#! /usr/bin/python
import sys
if (len(sys.argv) > 1):
num=int(sys.argv[1])
else:
num=int(raw_input(“How many nodes are in your cluster? “))
for i in range(0, num):
print ‘token %d: %d’ % (i, (i*(2**127)/num))[/code]
3. 저장하고 만들어진 파일이 실행가능하도록 실행 권한을 부여합니다.
[code]chmod +x tokengentool[/code]
4. 스크립트를 수행합니다.(당연히 시스템에 파이썬이 깔려있어야 합니다.)
[code]./tokengentool[/code]
5. 질문이 뜨면 클러스터를 구성하기 위한 노드의 수를 입력해 줍니다.
[code]How many nodes are in your cluster? 6
token 0: 0
token 1: 28356863910078205288614550619314017621
token 2: 56713727820156410577229101238628035242
token 3: 85070591730234615865843651857942052864
token 4: 113427455640312821154458202477256070485
token 5: 141784319550391026443072753096570088106[/code]
6. 위의 값을 가지고 각각의 노드들의 cassandra.yaml파일의 initial_token값을 설정하도록 합니다.
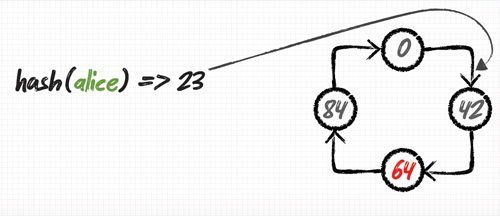
이미 운영중인 노드의 밸런스 조정하기
1. 다음과 같이 밸런스가 무너진 시스템을 조정하도록 하겠습니다. (다음은 내용을 요약하였습니다.)
[code]# nodetool -h localhost ring
Address Owns
192.168.0.104 36.65%
192.168.0.103 38.05%
192.168.0.105 9.59%
192.168.0.101 9.60%
192.168.0.102 6.11%[/code]
2. 위에서 사용한 tokengentool을 사용하여 5대의 노드의 토큰을 생성합니다.
[code]How many nodes are in your cluster? 5
token 0: 0
token 1: 34028236692093846346337460743176821145
token 2: 68056473384187692692674921486353642291
token 3: 102084710076281539039012382229530463436
token 4: 136112946768375385385349842972707284582[/code]
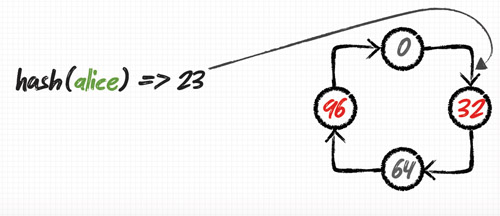
3. nodetool의 move명령을 사용하여 위의 노드로 이동을 시킵니다. 노드를 넘나드는 이동의 경우 매우 오래 걸립니다.
[code]// 192.168.0.102 노드의 예
# nodetool -h localhost move 34028236692093846346337460743176821145[/code]
4. 노드간의 밸런스 조정 완료 후(특정노드에만 부하가 가중되던 문제가 해결됨)
[code]# nodetool -h localhost ring
Address Owns
192.168.0.101 20.00%
192.168.0.102 20.00%
192.168.0.103 20.00%
192.168.0.104 20.00%
192.168.0.105 20.00%[/code]
참고: http://www.datastax.com/docs/0.8/install/cluster_init#cluster-init