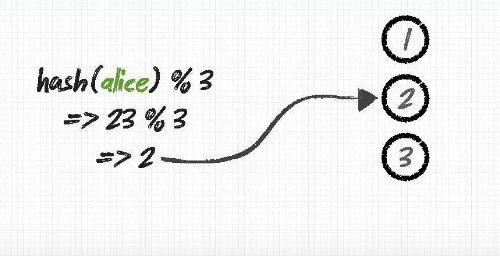
Java용으로 쓸만한 Cassandra 클라이언트 라이브러리를 찾다보니 대충 Pelops, Hector, Kundera정도로 나뉘어 지는것 같더군요. 셋중에 무엇이 가장 좋은가를 놓고 비교해 보자면 다양한 결론이 나오겠지만 Kundera에서 자체적으로 내놓은 퍼포먼스 테스트 결과가 있습니다. 퍼포먼스만 달랑 놓고 보면 Kundera가 가장 떨어지는 결과를 보여주니 일부러 거짓말 하는 데이터는 아닌것 같아 보입니다.
Kundera Performance 발번역
Kundera의 퍼포먼스를 Hector / Pelops와 비교해 보았습니다. 왜 Hector / Pelops인가요? Kundera는 데이터 저장소에 객체를 매핑해주는 툴이고 Hector / Pelops는 하이 레벨의 Cassandra 클라이언트입니다. 그렇기 때문에 이 비교는 논란이 될 수 있습니다. 이 비교의 의도는 Kundera 가 추가적으로 제공하는 매핑이나 다른 멋진 기능들의 오버헤드가 얼마나 되는지 계산해 보기 위함입니다.
Kundera – Cassandra는 Lucene기반의 인덱싱을 제공하며 그렇기 때문에 Hector/Pelops가 할수 있는 것들외에 추가적인 작업이 가능합니다. 그러므로 테스트는 이 Lucene인덱싱을 사용할때와 안할때 두가지 시나리오를 가지고 진행됩니다. 전자는 이 추가적인 인덱싱 기능을 사용하지 않으므로 비교해볼만한 상대가 될지 모르겠지만 후자의 경우에는 인덱싱을 내장 지원하기 때문에 비교대상이라 보기 어려운 퍼포먼스를 보여주긴 합니다.
Kundera Without Indexing Support
Bulk Load:
| Number Of Records (Single Thread) |
Pelops Time (in ms) |
Hector Time (in ms) |
Kundera (in ms) |
| 1 | 22 | 56 | 82 |
| 1000 | 550 | 666 | 925 |
| 4000 | 1791 | 1928 | 2952 |
| 40000 | 10533 | 10645 | 12392 |
| 100000 | 23832 | 24675 | 25994 |
| 1000000 | 221154 | 229619 | 236242 |
Concurrent Load:
| Number Of Threads (1 record) |
Pelops Time (in ms) |
Hector Time (in ms) |
Kundera (in ms) |
| 10 | 53 | 57 | 80 |
| 100 | 232 | 259 | 250 |
| 1000 | 1560 | 1443 | 1718 |
| 10000 | 9120 | 8514 | 10127 |
| 40000 | 28869 | 28330 | 29506 |
| 50000 | 36454 | 34823 | 36336 |
| 100000 | 68586 | 65513 | 69513 |
Concurrent Load + Bulk Load:
| Number Of Threads (1000 rec/ thread) |
Pelops Time (in ms) |
Hector Time (in ms) |
Kundera (in ms) |
| 10 | 3968 | 4434 | 5085 |
| 100 | 21560 | 22329 | 25274 |
| 1000 | 227232 | 207834 | 226541 |
Kundera With Indexing Support
Bulk Load:
| Number Of Records (Single Thread) |
Pelops Time (in ms) |
Hector Time (in ms) |
Kundera (in ms) |
| 1 | 25 | 40 | 93 |
| 1000 | 677 | 957 | 1719 |
| 4000 | 2131 | 2429 | 3901 |
| 40000 | 13009 | 13075 | 22158 |
| 100000 | 28884 | 30097 | 44876 |
| 1000000 | 256986 | 262067 | 375137 |
Concurrent Load:
| Number Of Threads (1 record) |
Pelops Time (in ms) |
Hector Time (in ms) |
Kundera (in ms) |
| 10 | 53 | 56 | 118 |
| 100 | 232 | 281 | 552 |
| 1000 | 1560 | 1823 | 2762 |
| 10000 | 9120 | 9776 | 14104 |
| 40000 | 28869 | 32331 | 39549 |
| 50000 | 36454 | 37172 | 50099 |
| 100000 | 68586 | 74304 | 95410 |
Concurrent Load + Bulk Load:
| Number Of Threads (1000 rec/ thread) |
Pelops Time (in ms) |
Hector Time (in ms) |
Kundera (in ms) |
| 10 | 4343 | 4738 | 9546 |
| 100 | 26010 | 24619 | 35196 |
| 1000 | 227232 | 219247 | 308975 |
위의 단순한 결과들로만 보면 Kundera는 모든 면에서 다른 라이브러리에 비교해 뒤쳐지는 속도를 보여줍니다. 하지만 Kundera는 Lucene인덱싱 POJO에 직접적인 데이터 매핑등 사용상에 많은 장점을 가지고 있습니다. 대충 검색해 보았을때는 Kundera는 Full-Text 검색도 지원한다고 합니다. 사실상 NoSQL에서 지원하기 어려운 점들입니다. 사용해 보진 않았지만 다양한 기능을 제공하는것으로 보여집니다.
참고: https://github.com/impetus-opensource/Kundera/wiki/Kundera-Performance