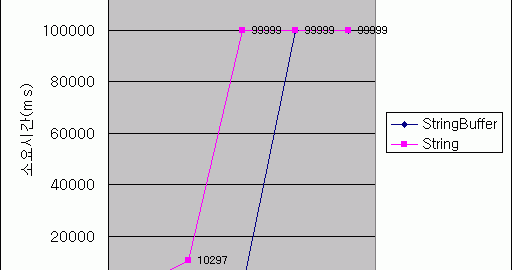
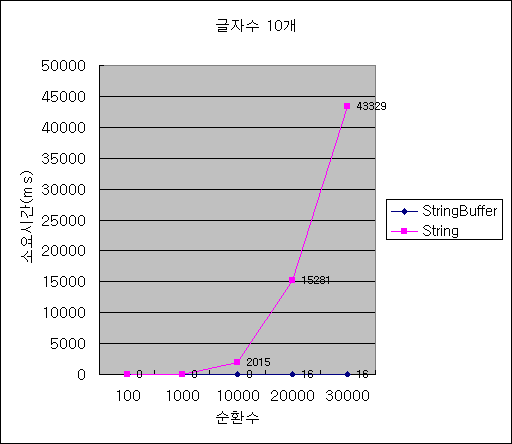
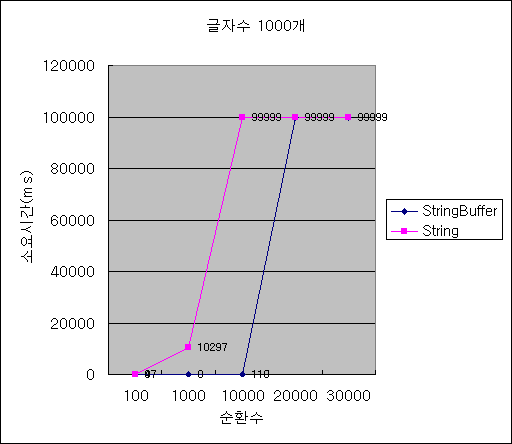
1. 다음 용어들을 간략히 설명하라.
엔티티
엔티티는 사람, 장소, 사물, 사건등과 같이 독립적으로 존재하면서 고유하게 식별이 가능한 실세계의 객체이다.
엔티티 타입
엔티티들은 엔티티 타입들로 분류된다. 엔티티 집합은 동일한 애트리뷰트들을 가진 엔티티들의 모임이다. 엔티티 타입은 동일한 애트리뷰트들을 가진 엔티티들의 틀이다. 엔티티 타입은 관계 모델의 릴레이션의 내포에 해당하고, 엔티티 집합은 관계 모델의 릴레이션의 외연에 해당한다.
단순 애트리뷰트
단순 애트리뷰트는 더 이상 다른 애트리뷰트로 나눌수 없는 애트리뷰트이다. 단순 애트리뷰트는 ER다이어그램에서 실선 타원으로 표현한다.
복합 애트리뷰트
복합 애트리뷰트는 두 개 이상의 애트리뷰트로 이루어진 애트리뷰트이다. 동일한 엔티티 타입에 속하는 애트리뷰트들 중에서 밀접하게 연관된 것을 모아놓은 것이다.
다치 애트리뷰트
다치 애트리뷰트는 각 엔티티마다 여러개의 값을 가질수 있는 애트리뷰트이다. 예를 들어, 사원은 여러 개의 취미를 가질수 있으므로 사원 엔티티 타입에 취미 애트리뷰트가 있다면 다치 애트리뷰트로 지정해야 한다. 다치 애트리뷰트는 ER다이어그램에서 이중선 타원으로 표현한다.
유도된 애트리뷰트
유도된 애트리뷰트는 다른 애트리뷰트의 값으로부터 얻어진 애트리뷰트이다. 예를 들어 Age(나이) 애트리 뷰트는 주민등록번호 애트리뷰트로부터 유도될수 있는 애트리뷰트이다.
탐색 키
인덱스가 정의된 필드를 탐색키라고 부른다. 탐색키의 값들은 후보 키 처럼 각 튜플마다 반드시 고유하지는 않다.
히프 파일
히프 파일은 가장 단순한 파일 조직이다. 일반적으로 레코드들이 삽입된 순서대로 파일에 저장된다. 일반적으로 새로 삽입되는 레코드를 파일의 가장 끝에 첨부되는데,파일 중간에 빈공간이 있으면 거기에 삽입할수도 있다.
클러스터링 인덱스
클러스터링 인덱스는 탐색키에 따라 정렬된 데이터 파일에 대해 정의된다. 각 데이터 블록 대신에 각각의 상이한 키 값마다 하나의 인덱스 엔트리가 인덱스에 포함되어, 그 키 값을 갖는 첫 번째 레코드의 주소(또는 레코드가 들어있는 블록의 주소)를 가르킨다.
밀집 인덱스
밀집 인덱스는 각 레코드의 키 값에 대해서 인덱스에 엔트리를 유지하는 인덱스를 말한다.
희소 인덱스
희소 인덱스는 일부 키 값에 대해서만 인덱스에 엔트리를 유지하는 인덱스를 말한다. 일반적으로 각 블록마다 한 개의 탐색 키 값이 인덱스 엔트리에 포함된다.
다단계 인덱스
원래의 인덱스를 1단계 인덱스라 하고 이 인덱스에 대해 정의한 추가 인덱스를 2단계 인덱스라고 한다. 교재에 따라서는 새로 추가된 인덱스를 1단계, 기존의 인덱스를 2단계라고 부르기도 한다. 다단계 인덱스는 가장 상위 단계의 모든 인덱스 엔트리들이 한 블록에 들어갈수 있을때 까지 이런 과정을 반복한다. 가장 상위 단계 인덱스를 마스터 인덱스라고 부른다.
2. 엔티티 타입이 무엇인가? 정규 엔티티 타입과 약한 엔티티 타입의 차이점이 무엇인가?
정규 엔티티 타입은 독자적으로 존재하며 엔티티 타입 내에서 자신의 키 애트리뷰트를 사용하여 고유하게 엔티티들을 식별할 수 있는 엔티티 타입을 의미한다. 이에 반해서 약한 엔티티 타입은 키를 형성하기에 충분한 애트리뷰트들을 갖지 못한 엔티티 타입이다.
4. 관계 타입이 무엇인가? 관계 타입의 차수가 무엇인가? 순환 관계가 무엇인가?
관계는 엔티티들 사이에 존재하는 연관이나 연결로서 두 개 이상의 엔티티 타입들 사이의 사상으로 생각할수 있다. 연관된 엔티티들은 동일한 타입이거나 서로 다른 타입일 수 있다.
관계 타입의 차수는 관계로 연결된 엔티티 타입들의 개수를 의미한다. 따라서 1진, 2진, 3진 관계를 각각 차수가 1, 2, 3 이다. 임의의 개수의 엔티티 타입 사이의 관계를 정의할수 있지만 실세계에서 가장 흔한 관계는 두 개의 엔티티 타입을 연결하는 2진 관계이다.
순환 관계는 하나의 엔티티 타입이 동일한 관계 타입에 두 번이상 참여하는 것이다.
6. 아래의 ER 다이어그램에서 두 개의 엔티티 타입과 한 개의 관계 타입이 있다. 한 프로그래머가 어떤 프로젝트에서 몇 시간 동안 일했는가를 나타내는 NumOfHours라는 애트리뷰트를 포함시키려 한다. 이 애트리뷰트가 어디에 속해야 하는가?

7. 카디날리티 비율과 참여 제약 조건을 합쳐서 구조적 제약조건이라고 부른다. 카디날리티 비율은 1:1, 1:N, M:N 중의 하나이다. 참여 제약 조건은 전체 참여와 부분 참여로 구분한다. 총 몇가지 구조적 제약조건이 가능한가?
총 5가지 (1:1 전체참여, 1:N 전체참여, 1:N 부분참여, M:N 전체참여, M:N 부분참여)
9. 아래의 ER 다이어그램을 릴레이션들로 변환하라.
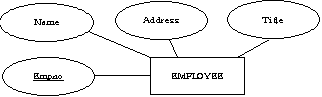
Employee |
Empno |
Name |
Address |
Title |
|
|
|
|
11. 아래의 ER 다이어그램을 릴레이션들로 변환하라.
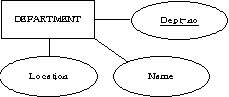
Department |
Dept-no |
Name |
Location |
|
|
|
15. 일반적으로 데이터베이스 설계단계에서 고려되는 두가지 제약 조건이 무엇인가?
카디날리티 비율, 참여 제약 조건
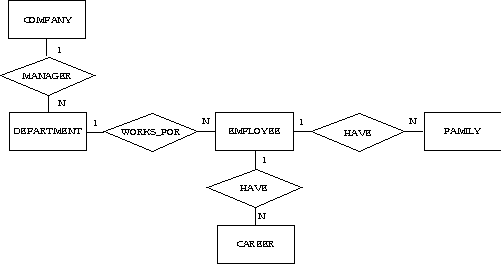
21. 벤처기업협회에서 각 회원사에 대한 정보를 유지하려 한다. 아래의 각 설명에 대하여 ER 다이어그램을 그려라.
(1) 각 회사는 다섯 개 이하의 부서를 유지한다. 각 부서는 한 회사에만 속한다.

(2) (1)의 각 부서에는 한명 이상의 사원들이 근무한다. 각 사원은 한 부서를 위해서만 일한다.

(3) (2)의 각 사원은 부양가족을 안 갖거나 한명 이상의 부양가족을 가질수 있다. 각 부양가족은 한 사원에게만 속한다.

(4) (3)의 각 사원은 고용 이력을 가질수도 있고 안가질수도 있다.

(5) (1) ~ (4)까지 개별적으로 작성한 ER 다이어그램을 한 개의 ER 다이어그램으로 통합하여 나타내라.
24. 아래와 같은 데이터베이스 설계의 주요 단계들을 정확한 순서대로 배열하라.
(논리적 설계, 데이터베이스 튜닝, 요구사항 수집과 분석, 물리적 설계, 정규화, 개념적 설계)
1. 요구사항 수집과 분석
2. 개념적 설계
3. 논리적 설계
4. 정규화
5. 물리적 설계
6. 데이터베이스 튜닝
25. 개념적 설계, 논리적 설계, 물리적 설계의 차이점을 설명하라.
개념적 설계 단계는 모든 물리적인 사항과 독립적으로, 한 조직체에서 사용되는 정보의 모델을 구축하는 과정이다. 사용자들의 요구사항 명세로부터 개념적 스키마가 만들어진다. 개념적 설계 단계의 결과물은 논리적 설계 단계의 입력으로 사용된다.
논리적 설계에서는 데이터베이스 관리를 위해 선택한 DBMS의 데이터 모델을 사용하여 논리적 스키마를 생성한다. 개념적 스키마에 알고리즘을 적용하여 논리적 스키마 생성한다.
물리적 설계에서는 처리 요구사항들을 만족시키기 위해 저장 구조와 인덱스 등을 결정한다. 물리적 설계에 영향을 미치는 요인으로는 트랜젝션들의 예상 수행 빈도, 트랜젝션들의 시간 제약 조건 등이 있다.
30. 카디날리티 비율 1:1, 1:N, M:N에 대해서 본문에서 설명하지 않은 실생활의 예를 하나씩 들어라.
1:1관계 예 : 전구를 꼽을수 있는 소켓을 엔티티 A라고 하고 전구를 엔티티 B라고 할때 A와 B는 1:1 관계를 갖는다.
1:N관계 예 : 공중 화장실을 엔티티 A라고 하고 화장실 안의 변기를 엔티티 B라고 할때 A와 B의 관계는 1:N 관계이다.
M:N관계 예 : 한 빌딩안에 있는 사람을 태우는 엘리베이터들을 엔티티 A라고 하고, 탑승하는 사람을 엔티티 B라고 할때 A와 B는 M:N 관계이다.