


PHP에서 간단한 프로젝트를 생성하는데 도움이 되는 프레임워크로 CodeIgniter(코드이그나이터)가 괜찮은것 같습니다. PHP와 카산드라가 통신하기 위해서는 thrift를 시용해야 하는데요 [이글]에 관련된 설치에 대해 적어두었습니다. 이제 간단하게 연동하는 방법에 대해 적어보도록 하겠습니다.
1. Cassandra 설치하기
[이글]에 관련된 글을 적어두었습니다. 리눅스 기반이긴 하지만 윈도우라고 해서 크게 다르진 않을것이라 생각합니다.
2. CodeIgniter 설치하기
http://codeigniter.com/ 에 방문하여 CodeIgniter의 최신 소스를 다운받아 서버에 업로드하여 적당한 위치에 압축을 풀어주도록 합니다. 이후에 application/config/config.php파일을 수정하여 줍니다.
[code php]// 원하는 프로젝트의 루트 디렉토리 URL을 적어줍니다. 끝에 꼭 /를 붙입니다.
$config[‘base_url’] = ‘http://theeye.pe.kr/codeigniter/’;
// mode_rewrite를 사용하기 위해 기본값을 제거합니다
$config[‘index_page’] = ”;[/code]
프로젝트의 루트디렉토리에 .htaccess파일을 생성합니다.
[code]RewriteEngine on
RewriteCond $1 !^(index\.php|images|robots\.txt)
RewriteRule ^(.*)$ /index.php/$1 [L][/code]
3. PHPCassa 설치하기
[이글]을 참고하셔서 PHPCassa의 소스를 다운받도록 합니다. PHPCassa의 위치는 application/libraries/phpcassa로 올리면 됩니다.
4. CodeIgniter 추가 설정하기
application/config/cassandra.php 파일을 생성합니다. 다음과 같은 정보를 기입하도록 합니다.
[code]<? if ( ! defined(‘BASEPATH’)) exit(‘No direct script access allowed’);
$config[‘cassandra’] = array();
// 노드의 갯수만큼 배열로 정의한다.
$config[‘cassandra’][‘nodes’] = array(‘localhost:9160’);
// 기본적으로 사용할 키스페이스 이름을 정의한다.
$config[‘cassandra’][‘keyspace’] = ‘Keyspace1’;
?>[/code]
application/libraries/cassandra.php 파일을 생성합니다. 다음과 같은 코드를 작성합시다.
[code php]<?
require_once(‘phpcassa/connection.php’);
require_once(‘phpcassa/columnfamily.php’);
require_once(‘phpcassa/uuid.php’);
class Cassandra
{
private $_CI;
private $_config;
private $_connection;
private $_columnfamily;
public function __construct()
{
$this->_CI = & get_instance();
$this->_CI->config->load(‘cassandra’);
$this->_config = $this->_CI->config->item(‘cassandra’);
$this->_connection = new ConnectionPool($this->_config[‘keyspace’],
$this->_config[‘nodes’]);
$this->_columnfamily = array();
}
public function cf($columnfamily)
{
if(!isset($this->_columnfamily[$columnfamily]))
{
$this->_columnfamily[$columnfamily] = new ColumnFamily($this->_connection, $columnfamily);
}
return $this->_columnfamily[$columnfamily];
}
public function uuid($ver = 1)
{
return UUID::mint($ver);
}
}
?>[/code]
사실 uuid메서드에 대해서는 좀더 생각해 볼점이 있습니다. 자세한 내용은 PHPCassa의 columnfamily.php의 주석들을 참고하시기 바랍니다.
5. 테스트 컨트롤러 작성하기
제대로 작동하는지 테스트를 하기 위해 controllers/test.php 를 작성하도록 합니다.
[code php]<?
class Test extends CI_Controller
{
public function __construct()
{
parent::__construct();
// 카산드라를 사용하기 위해 라이브러리를 로드합니다.
$this->load->library(‘cassandra’);
}
public function index()
{
// 사용을 하기 원하는 컬럼패밀리를 선택합니다.
$cf = $this->cassandra->cf(‘Standard1’);
// 값 가져오기 (PHPCassa 메서드 참고)
var_dump($cf->get(‘row_key’));
// Timestamp UUID값 테스트
echo $this->cassandra->uuid();
}
}
?>[/code]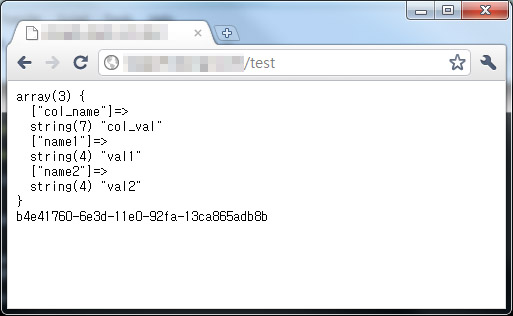 참고:
참고:
http://crlog.info/2011/04/07/apache-cassandra-phpcassa-code-igniter-large-scale-php-app-in-5-minutes/
