JAVASCRIPT에는 순수 자바 스크립트 이외에 이것이 있습니다.
바로 DOM(Document Object Model)입니다.
이것은 객체로 이루어진 문서를 뜻합니다. 또한 그 객체들은 어떤 규칙을 가지고 있습니다.
[code]<!DOCTYPE html PUBLIC “-//W3C//DTD XHTML 1.1//EN” “http://www.w3.org/TR/xhtml1/DTD/xhtml1.dtd“>
<html xmlns=”http://www.w3.org/1999/xhtml” xml:lang=”en”>
<head>
<meta http-equiv=”content-type” content=”text/html;charset=utf8″/>
<title>내친구들</title>
</head>
<body>
<h1>내친구들</h1>
<ul>
<li>홍길동</li>
<li>이순신</li>
<li>유관순</li>
</ul>
</body>
</html>[/code]
위와 같은 (X)HTML 문서는 다음과 같은 Tree구조로도 표현될 수 있습니다.
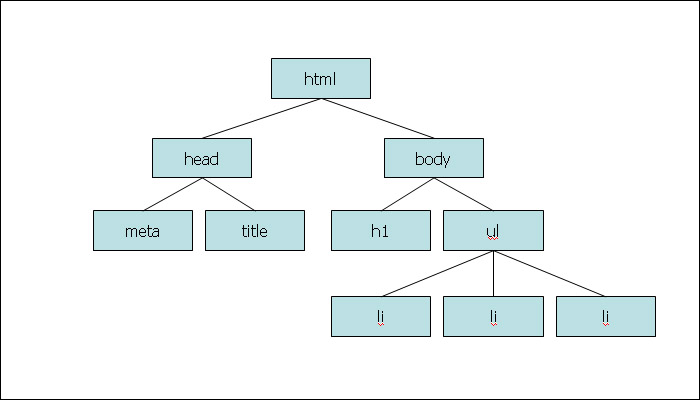
최상단에는 html 엘리먼트가 존재합니다. 그 밑에는 head와 body가 존재하죠. 그 밑으로도 엘리먼트들이 연결되어있습니다.
h1 엘리먼트는 body의 자식 엘리먼트입니다. 반대로 body 엘리먼트는 h1에게 있어 부모가 됩니다.
이 각각의 연결되어있는 엘리먼트들을 노드(Node)라고 부릅니다.
[code]<p title=”이것은 속성입니다”>이것은 텍스트입니다</p>[/code]
위의 것은 이렇게 말로써 표현할 수 있습니다.
- p 엘리먼트(Element) 노드가 있다.
- title 속성(Attribute) 노드가 있다.
- “이것은 텍스트입니다”라는 문구의 텍스트(Text) 노드가 있다.
이제 자바스크립트를 이용하여 엘리먼트 노드에 접근하는 것을 해보기로 하지요.
[code]<p id=”melon” title=”과일”>멜론은 맛있어</p>[/code]
위와 같은 p 엘리먼트 노드를 가져오기 위하여 javascript에서는 다음과 같은 명령을 사용할 수 있습니다.
[code]var element = document.getElementById(‘melon’);
alert(“엘리먼트 ID : ” + element.id);
alert(엘리먼트 TITLE : ” + element.title);[/code]
감이 오시나요? document는 DOM의 최상위 객체입니다. 특정 객체 이하에서 엘리먼트를 검색할 수도 있습니다.
[code]var element = document.getElementById(‘fruits’);
var subElement = element.getElementById(‘melon’);[/code]
2. getElementsByTagName
위의 예제에서 볼 수 있는 html, body, h1, ul, li등은 Tag명이라고 합니다. 그렇다면 이 태그명을 가지고 엘리먼트 노드를 가져올수도 있겠네요.
[code]vat tagElements = document.getElementsByTagName(‘li’)[/code]
위의 명령문을 실행하면 document이하의 모든 li 엘리먼트 노드를 찾아 배열로 반환합니다.
getElementById와 다른점이 있다면 바로 이것, 꼭 배열로 반환한다는것입니다.
제일 처음에 나온 소스를 예로 들었을 경우 다음과 같이 활용 할 수 있습니다.
[code]var items = document.getElementsByTagName(‘li’);
for(var i = 0 ; i < items.length ; i++) {
alert(items[i].innerHTML)
}[/code]
모든 li를 찾아서 해당 텍스트 노드의 값을 출력하는 예제입니다.
li뿐만 아니라 *를 사용하며 전체 엘리먼트를 가져올 수도 있습니다.
3. childNodes
특정 엘리먼트 노드의 자식 노드를 배열로 담고 있습니다. 다음의 예제를 보도록 하죠
HTML :
[code]<ul id=”parent”>
<li>홍길동</li>
<li>이순신</li>
<li>유관순</li>
</ul>[/code]
JAVASCRIPT :
[code]var ul = document.getElementById(‘parent’);
var childs = ul.childNodes;
for(var i = 0 ; i < childs.length ; i++) {
alert(childs[i].innerHTML);
}[/code]
4. parentNode
이 것으로 부모 엘리먼트 노드를 가져올 수 있습니다.
HTML :
[code]<ul>
<li>홍길동</li>
<li id=”child”>이순신</li>
<li>유관순</li>
</ul>[/code]
JAVASCRIPT :
[code]var child = document.getElementById(‘child’);
var parent = child.parentNode;
alert(parent.tagName); // 부모 태그인 UL이 출력됨[/code]
5. nextSibling
이녀석은 매우 특이하면서도 유용한 명령입니다.
같은 깊이(Depth)내에서 다음 엘리먼트 노드를 가리키고 있습니다. 마치 LinkedList에서 다음 노드를 가리키는 것과 흡사하겠네요.
HTML :
[code]<ul>
<li id=”target”>홍길동</li>
<li>이순신</li>
<li>유관순</li>
</ul>[/code]
JAVASCRIPT :
[code]var target = document.getElementById(‘target’);
var nextElement = target.nextSibling;
alert(nextElement.innerHTML); // ‘이순신’이 출력됨[/code]
하지만 여기서 주의할 점이 있습니다. nextSibling의 경우 IE와 FF의 처리가 조금 다른 부분이 있습니다.
[code]<li id=”target”>홍길동</li><!– FF의 경우 이곳에 줄바꿈 텍스트 노드가 있다고 생각함 –>
<li>이순신</li>[/code]
그러므로 위의 예제는 IE에서는 ‘이순신’이 출력되겠지만 FF에서는 빈 텍스트 노드가 출력됩니다.
모든 브라우저에서 동일하게 다음 엘리먼트로 이동하는 함수를 각자 만들어 쓰시면 될꺼 같네요.
자매품으로 previousSibling도 있습니다.