오랜만에 Spring을 만져보게 되었는데 3.x로 오면서 예전에 바래왔던것들이 상당부분 적용 된것 같네요. 특히 완벽한 어노테이션 환경이 도입된거 같아 좋습니다. 어노테이션으로 할 수 있는 것들이 엄청나게 많아졌네요. component scan 한방에 모든게 해결되는 느낌입니다.
오랜만에 Spring을 만져보게 되었는데 3.x로 오면서 예전에 바래왔던것들이 상당부분 적용 된것 같네요. 특히 완벽한 어노테이션 환경이 도입된거 같아 좋습니다. 어노테이션으로 할 수 있는 것들이 엄청나게 많아졌네요. component scan 한방에 모든게 해결되는 느낌입니다.
예전에는 iBatis라는 ORM 라이브러리를 사용했었는데요. 당시에도 MyBatis라는것이 있었던걸로 알고 있었는데 지금보니 iBatis팀이 완전히 MyBatis로 이름을 바꿔 옮겨간것이군요. iBatis의 운명은 사실상 끝나는것이 아닐까 하는 생각이 드는군요. 아무튼 이전개발자들이 똑같은 호환성으로 계속해서 업그레이드 해나간다는 MyBatis를 스프링에 연동해 보기로 하겠습니다. 근데 정말 희안하게도 스프링에서 사실상 myBatis와의 연동을 지원하지 않는군요. 언제쯤 정식 지원할지 모르겠지만 아무튼 연동하기 위한 라이브러리 또한 구할 수 있습니다.
Spring 프레임워크 다운로드 :
http://www.springsource.org/spring-framework
MyBatis 라이브러리 다운로드 :
http://code.google.com/p/mybatis/downloads/list?can=3&q=%22mybatis-3%22+-migrations
MyBatis Spring 연동 라이브러리 다운로드 :
http://code.google.com/p/mybatis/downloads/list?can=3&q=Product%3DSpring
Spring 프레임워크를 이용한 프로젝트를 세팅하는 방법은 생략하도록 하겠습니다. 예전에 썼던글이지만 [이곳]을 참고하시는것도 괜찮을것 같습니다. 프로젝트에 다운받은 다음의 라이브러리를 추가합니다. (현재 글쓴 시점의 버전으로 적어두겠습니다)
mybatis-3.0.6.jar mybatis-spring-1.0.2.jar
context 설정에 다음의 bean들을 추가해 줍니다.
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource"
destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<property name="url" value="${jdbc.url}" />
<property name="username" value="${jdbc.user}" />
<property name="password" value="${jdbc.password}" />
</bean>
<bean id="sqlSessionFactory"
class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="mapperLocations"
value="classpath:kr/pe/theeye/dao/mapper/*.xml" />
</bean>
<bean id="sqlSession" class="org.mybatis.spring.SqlSessionTemplate">
<constructor-arg index="0" ref="sqlSessionFactory" />
</bean>
여기서 대부분의 설정은 보시면 어떤 의미를 갖는지 단번에 이해하실것 같은데 굳이 설명해 보자면 sqlSessionFactory빈을 정의할때 사용되는 mapperLocations에 대해 첨언을 해보자면 위와같이 쿼리 매핑을 위한 XML파일을 검색하여 자동 추가하도록 설정할 수 있습니다. 만약에 위의 설정을 다음과 같이 한다면 하위 디렉토리의 모든 파일을 검색하게 됩니다.
<property name="mapperLocations" value="classpath:kr/pe/theeye/dao/mapper/**/*.xml" />
자, 여기까지만 보면 기존의 iBatis 2.x대를 사용하시던 분들이 보기에도 특별히 새로울것이라곤 없습니다. 그냥 클래스 이름 몇개 바뀌었나 싶을 정도밖에 안되죠. 그런데 여기서 중요한 개념이 한가지 추가되었습니다.
kr.pe.theeye.dao 패키지 위치에 ExampleDao 인터페이스 생성
public interface ExampleDao
{
public String getUserName(@Param("userId") String userId);
}
kr.pe.theeye.dao.mapper 패키지 위치에 ExampleMapper.xml 생성
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="kr.pe.theeye.dao.ExampleDao">
<select id="getUserName" parameterType="string" resultType="string">
SELECT USER_NAME FROM USERS WHERE USER_ID = #{userId}
</select>
</mapper>
여기서 매우매우 중요한점은 DAO클래스를 일단 인터페이스로 선언을 하고 iBatis에서 namespace는 선택사항이었지만 지금부터는 필수라는것입니다. namespace에는 패키지명을 포함한 DAO인터페이스의 경로를 정확히 써줍니다. 그리고 각각의 쿼리문들의 id는 DAO인터페이스에서 정의한 메소드명과 일치하여야 합니다.
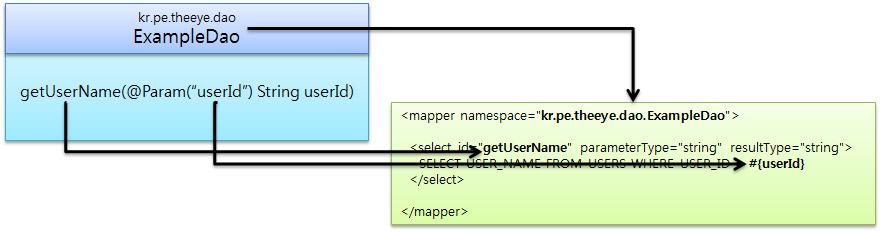
한번 그림으로 그려보았습니다. 이제 사실상 준비는 끝났습니다. 이제 컨트롤러에서 sqlSession빈을 가져다 쓰시면 됩니다.
@Controller
public class ExampleController
{
@Autowired
private SqlSession sqlSession;
@RequestMapping("/test/mybatis/{userId}")
@ResponseBody
public String testMybatis(@PathVariable("userId") String userId)
{
ExampleDao exampleDao = sqlSession.getMapper(ExampleDao.class);
return exampleDao.getUserName(userId);
}
}
위와 같이 DAO를 꺼내쓰기만 하면 실제 쿼리가 XML에 정의된 쿼리들과 자동 매핑되어 결과값이 반환됩니다. 특별히 바뀐부분은 이 부분이 대부분이라 나머지 부분은 iBatis를 쓰시던 분들도 레퍼런스 조금만 들여다 보시면 바로 적용하실 수 있을것으로 보입니다.
위와 다르게 단순히 어노테이션 만으로 쿼리문을 작성한다던가 코드를 작성하듯이 쿼리문을 짠다던가 다양한 방법을 MyBatis에서 제공하고 있지만 기존의 iBatis사용자들이 가장 익숙하게 갈아탈 수 있는 방법은 이런 방법이 아닐까 생각됩니다. DAO인터페이스들을 구현하여 사용하는등의 다양한 방법론들이 있지만 그런것은 개발자분들의 의향에 맞게 설계하시면 될 것 같습니다. 다른 예제들은 레퍼런스에 잘 나와있습니다.