

이번에는 카산드라를 사용하여 다수의 서버들간의 클러스터링을 구성하는 방법에 대해 간단히 기록해 보도록 하겠습니다.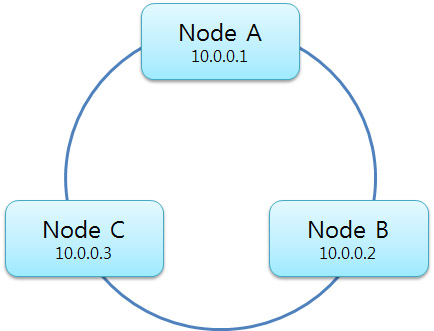
테스트로 3대의 노드를 이용하여 하나의 클러스터를 구성하겠습니다. 카산드라에서는 기본적으로 Ring 형태의 노드 구성을 이루게 됩니다. 위의 구성에서 우리는 A노드를 Seed 노드라고 할 것입니다. 이 Seed 노드는 이 클러스터에 새롭게 참가(Join)하는 노드가 있을경우 노드 구성을 알려주는 역할을 합니다.
카산드라 클러스터 구성하기
Node A 설치하기
[code]conf/cassandra.yaml[/code]
위의 설정 파일을 변경하도록 합니다. Node A는 Seed노드이면서 이 클러스터를 첫번째로 존재하게 하는 노드입니다. 다음을 설정하도록 합시다.
cluster_name: ‘Test Cluster’
위의 설정은 이 클러스터의 이름을 설정합니다. 클러스터란 다수의 노드가 모여있는 집합이라고 보시면 됩니다. 하나의 클러스터에 참가하기 위해서는 모두 같은 cluster_name을 가지고 있어야만 합니다. 여기의 이름값이 다를경우 이후의 노드들은 이 클러스터에 참여할 수 없습니다.
auto_bootstrap: false
카산드라에서 부트스트랩이란 자신이 부족한 데이터를 주변의 노드들로부터 가져오는 과정(동기화)을 말합니다. 새롭게 참가하는 노드들은 클러스터의 데이터들을 동기화하면서 참여하여야 합니다. 하지만 Seed노드는 자신이 첫번째 노드이기 때문에 이 과정을 생략합니다.
seeds:
– 10.0.0.1
시드 노드를 설정합니다. 자기 자신인 경우 127.0.0.1로 하여도 무방하지만 꼭 자신의 IP를 지정하여주도록 합니다.
listen_address: 10.0.0.1
카산드라 서버들간에 통신을 하기 위해 설정해 주어야 하는 설정입니다. 값을 비워둘 경우 기본적으로 InetAddress.getLocalHost()를 호출하여 자신의 값으로 설정된다고 합니다만 잘 안되는것 같습니다. 필수적으로 자기 자신의 IP로 변경하여 줍니다. 여기서 이상한점이 listen은 외부로 해야할텐데 0.0.0.0을 사용해서는 안됩니다. 자신의 IP로 해도 잘 되므로 저렇게 하도록 합니다.
rpc_address: 0.0.0.0
이것이 Thrift를 이용한 클라이언트 접속을 허용하는 설정입니다. 0.0.0.0으로 설정할 경우 모든 원격지 접속을 허용하게 됩니다. 적절히 값을 설정하도록 합니다.
Node B 설치하기
cluster_name: ‘Test Cluster’
Node A가 생성한 클러스터에 접속해야 하므로 꼭! 같은 클러스터 이름을 사용하도록 합시다.
auto_bootstrap: true
Node B부터는 기존의 클러스터에 참여한다는 성격이 강합니다. 기존에 생성된 데이터를 가져와 동기화를 할 필요가 있습니다.
seeds:
– 10.0.0.1
Seed 노드인 A노드의 주소를 입력하여 줍니다.
listen_address: 10.0.0.2
서버간의 통신을 위하여 자기 자신의 IP주소를 입력하여 줍니다.
rpc_address: 0.0.0.0
마찬가지로 클라이언트 접속을 허용할 IP 대역을 입력하여 줍니다.
Node C 설치하기
여기서부터는 설정이 중복되므로 간단히 내용만 적겠습니다.
cluster_name: ‘Test Cluster’
auto_bootstrap: true
seeds:
– 10.0.0.1
listen_address: 10.0.0.2
rpc_address: 0.0.0.0
클러스터 운영하기
노드의 연결상태 확인하기
Address Status State Load Owns Token
1595…794
10.0.0.1 Up Normal 78.85 KB 36.41% 5136…766
10.0.0.2 Up Normal 65.88 KB 8.76% 6627…220
[code][root@NodeA bin]# ./nodetool -h localhost ring
Address Status State Load Owns Token
1595…794
10.0.0.1 Up Normal 78.85 KB 36.41% 5136…766
10.0.0.2 Up Normal 65.88 KB 8.76% 6627…220
10.0.0.3 Down Normal 59.3 KB 54.83% 1595…794[/code]
만약에 하나의 노드가 죽게 된다면 위와 같이 Down으로 표시가 됩니다. 이경우 적당히 해당 노드를 제거하거나 혹은 해당 노드를 살려내야 합니다.
노드 제거하기
노드를 제거하기 위한 이유로는 대표적으로 2가지가 있을것 같습니다. 정상적인 목적에 의거하여 운영중인 노드를 제거하거나 또는 뜻하지 않은 장애로 서비스중인 클러스터에서 제거해야 하거나.
운영중인 노드를 제거하기 위해서는 decommission(퇴역)이라는 멋진 이름의 명령을 사용합니다.
[code][root@NodeC bin]# ./nodetool -h localhost decommission[/code]
하지만 위와같은 정상적인 명령을 사용할 수 없을때가 있습니다. 예를 들면 현재 노드에서 삭제중이지만 몇시간동안 그상태로 먹통이 된 경우도 있을 수 있습니다. 삭제 명령을 받았지만 아직도 떠나는중(Leaving)????
[code]10.0.0.3 Down Leaving 218.71 KB 21.76%[/code]
이경우에는 removetoken을 사용하여 강제로 노드를 제거할 수 있습니다.
[code][root@NodeA bin]# ./nodetool -h localhost removetoken 1595…794[/code]
삭제하고자 하는 노드와 정상적으로 통신을 할 수 없는 상태라도 토큰을 이용하여 강제로 노드를 제거할 수 있습니다.
데이터 Fail Over 전략
사실 이름은 멋있지만 Fail Over랄껀 없고 Replication을 통한 노드 한두개쯤 뻗어도 데이터는 손실이 일어나지 않는(않길 바라는..ㅠㅠ) 시스템을 구성하는 방법에 대해 적어보겠습니다. 사실 여기에 필요한 구성은 위에서 모두 끝냈습니다. 하지만 정말 신기하게도 위의 상황에서는 하나의 노드만 뻗어도 데이터를 가져오지 못하는 상황이 발생합니다. 뻗는 노드분의 데이터만 손실이 일어나는게 맞는거 같은데 이상하네요.
이제 키스페이스(Keyspace)를 만들어 보겠습니다.
[code][default@unkown] create keyspace Item with replication_factor = 3;[/code]
자 평범한듯 하지만 위의 키스페이스 생성 옵션중에 replication_factor라는 것이 있네요. 이것은 데이터를 몇군데에 복제할것인가를 정하는 것입니다. 한국인은 3을 좋아하니깐 3으로 해보았습니다.
사실 위의 예제에서는 노드가 3개뿐이기 때문에 2개 이상으로 복제를 하는것이 무의미한 이야기입니다. 하지만 미래에 노드가 늘어날것으로 기대하기 때문에 3으로 해두겠습니다.
[code][default@Item] list user;
Using default limit of 100
——————-
RowKey: park
=> (column=657874, value=686168616861, timestamp=1306150005971000)
1 Row Returned.
[default@Item] list user;
Using default limit of 100
null
[default@Item] list user;
Using default limit of 100
——————-
RowKey: park
=> (column=657874, value=686168616861, timestamp=1306150005971000)
1 Row Returned.[/code]
위의 예시는 서비스 운영중에 발생할수 있는 모습을 보여줍니다. Item이라는 replication_factor 3의 키스페이스가 있고 user 컬럼에는 하나의 Row가 존재합니다. 그리고 곧바로 다른 노드를 강제로 죽여보았습니다. 순간적으로 데이터가 없다고 나오네요. 그리고 이내 복구가 됩니다.